Table of Contents

Introduction
This article presents an in-depth analysis of the reliability and availability aspects within the context of decentralized storage systems, focusing on the innovative BNB Greenfield platform. The article explores the challenges associated with ensuring data reliability and availability in a decentralized environment and examines how BNB Greenfield addresses these challenges.
Through a comprehensive review of protocols, consensus mechanisms, and data distribution strategies, the article highlights the unique solutions employed by BNB Greenfield to guarantee data integrity and accessibility.
Core Concepts
Data Availability
Data Availability refers to the accessibility and correct storage of data on storage nodes or providers. In a decentralized storage system, data availability means that users can retrieve their stored data whenever they need it. It ensures that data is not lost, corrupted, or otherwise inaccessible due to failures or malicious actions. Data availability involves mechanisms that guarantee data can be retrieved from multiple nodes in the network, even if some nodes fail or become unavailable.
Data Reliability
Reliability refers to the consistency and trustworthiness of the data stored in the system. A reliable storage system ensures that the data retrieved is accurate and unaltered. It encompasses data integrity, ensuring that the data retrieved is the same as the data that was initially stored, and data authenticity, verifying that the data hasn’t been tampered with or altered maliciously.
Importance in Decentralized Storage
So to recap the difference between both:
- Data Availability: Focuses on ensuring that data can be accessed and retrieved from the storage system whenever required, regardless of failures or disruptions.
- Data Reliability: Focuses on ensuring that the data retrieved is accurate, consistent, and trustworthy, without any unauthorized changes or corruption.
And both data availability and reliability are crucial in the domain of decentralized storage:
Data Availability
- Users depend on decentralized storage for secure and convenient data storage and retrieval. Data availability ensures that users can access their data even if some storage nodes are offline or compromised.
- Distributed data storage relies on redundancy and replication to ensure data is available even when individual nodes fail.
- Availability is vital for maintaining user trust and ensuring the decentralization’s promise of data access anytime, anywhere.
Data Reliability
- In a trustless and decentralized environment, users need assurance that their stored data remains accurate and unaltered.
- Reliability prevents malicious actors from tampering with data or introducing counterfeit data, maintaining the integrity of the stored information.
- It’s essential for users who want to ensure their data remains unchanged and trustworthy over time.
Risks of Failure
In a decentralized storage ecosystem, achieving both data availability and reliability is essential for building trust, meeting user expectations, and ensuring the success of the platform. A failure in either aspect could lead to user dissatisfaction, loss of credibility, and potential legal and financial repercussions.
Users may lose access to their data, leading to frustration and inconvenience. Critical data might become unavailable when needed, affecting businesses, individuals, and applications that rely on it. And loss of data availability undermines the value proposition of decentralized storage systems.
In terms of data integrity, altered or tampered data could lead to misinformation, data breaches, or financial losses. Users might not be able to verify the authenticity of retrieved data, eroding trust in the system. And finally legal, financial, or regulatory implications can arise from unreliable data, especially in contexts where data accuracy is essential.
Availability and Reliability Approaches
In the realm of decentralized and distributed systems, ensuring data reliability and availability is paramount. These systems often involve multiple nodes or participants, each contributing to the storage and maintenance of data. Data reliability refers to the ability to ensure that the stored data is accurate, consistent, and accessible when needed.
Numerous projects in the blockchain and decentralized technology space aim to achieve data reliability and availability while addressing challenges such as the Sybil Attack, Outsourcing Attack, and Generation Attack, all related to replication integrity.
– Sybil Attack: This attack involves an adversary creating multiple fake identities that each claim to store replicas of the data.
– Outsourcing Attack: In this attack, an attacker fetches data from another provider and produces the proof as if it has been storing the data.
– Generation Attack: This attack is about an attacker creating data that can be regenerated on demand.
These challenges are crucial to address in decentralized storage networks, as they prevent attackers from exploiting vulnerabilities in storage proofs to gain network rewards without actually performing genuine storage. The prevention of the Generation Attack, in particular, is pivotal for building decentralized storage networks that can withstand adversarial actions.
In this article, we will explore how three prominent projects, namely Filecoin, Arweave, and Storj, approach these goals.
Filecoin’s Proof-of-Replication
Filecoin, a decentralized storage network, introduces Proof-of-Replication (PoRep) schemes as a means to establish data reliability and availability. PoRep allows a participant (prover) to commit to storing multiple distinct replicas of data and subsequently convince a verifier that these replicas are genuinely stored.
PoRep schemes are designed to establish trust in the storage of data replicas by enabling a prover to commit to storing multiple independent copies (replicas) of a piece of data and subsequently convince a verifier that these replicas are indeed being stored. These algorithms include Setup, Prove, and Verify functions. The Setup function initializes the scheme, the Prove function generates proofs based on the replica and challenges, and the Verify function checks the correctness of the proofs. The usage of zk-SNARKs reduces the amount of data storage providers need to transfer for them to prove their storage, reducing the costs associated with operating their services to the network.
To ensure the security of PoRep schemes, a game called RepGame is introduced. This game tests the ability of PoRep schemes to overcome the aforementioned challenges and demonstrates their distinction from other Proof-of-Storage (PoS) schemes.
Arweave’s Succinct Proofs of Random Access (SPoRA)
Arweave’s Proof of Reliability (SPoRA) is a consensus mechanism designed for the Arweave network, aiming to enhance the efficiency, decentralization, and energy consumption of the network.
Key Concepts and Mechanisms
– Search Space: SPoRA involves the continuous retrieval of chunks of past data, with each chunk identified by a global offset. This incentivizes the possession of any byte within the entire data weave. Search Space represents the set of offsets within a block, and its size is chosen to balance data retrieval efficiency and data replication incentives.
– Miner Steps: SPoRA utilizes a deterministic yet unpredictable process to choose candidate chunks. This process prevents miners from reducing the number of chunks they work with to save computational resources. RandomX, a proof-of-work algorithm optimized for CPUs, is used to implement the slow hash. Miners participating in SPoRA follow specific steps to mine a block. These steps involve generating a random nonce, computing a slow hash, searching local storage for a specific chunk, and verifying whether the computed hash meets the mining difficulty criteria. The solution chunk and its inclusion proof in the blockweave.
– Verifier Steps: Verifiers validate the mined blocks by iterating over the miner steps to ensure that the nonce and the chunk are correctly included in the verified block.
By incentivizing miners to replicate data more efficiently and swiftly, SPoRA improves the speed and availability of data on the network, enhancing the overall user experience.
Storj Coordination Avoidance
Storj Coordination Avoidance is implemented to enhance performance, scalability, and efficiency of the network to reduce coordination among storage node operators for optimal operation.
Storj tackles coordination challenges with two main methods:
Redundancy: Similarly to BNB Greenfield, Storj employs erasure codes for distributing file segments across the network, boosting durability and availability. This redundancy mitigates slow or faulty storage nodes’ impact. During uploads or downloads, if some nodes are sluggish, the network prioritizes faster responses. Sufficient redundant nodes providing required segments ensure user requests are fulfilled without latency disruption.
Coordination Avoidance: Unlike many decentralized systems relying heavily on blockchain consensus, Storj pragmatically avoids such consensus for file transfers. Blockchain consensus can introduce coordination overhead, hampering scalability and performance. Storj strives to ensure file transfer correctness without global consensus, opting for coordination avoidance.
Comparison vs BNB Greenfield
Proof of Challenge of BNB Greenfield stands apart from the approaches taken by Filecoin, Arweave, and Storj in several significant aspects.
| BNB Greenfield | Filecoin | Arweave | Storj | |
| Consensus-based | No | No | Yes | No |
| Redundancy | Erasure-Coding | Replication | Replication | Erasure-Coding |
| Resource intensive | No | zk-proofs | Consensus-based | No |
While blockchain networks offer robust guarantees, they often face coordination overhead. BNB Greenfield strategically avoids extensive blockchain consensus for file transfers, prioritizing practical correctness. However, it maintains blockchain consensus for payments. This two-fold approach optimizes BNB Greenfield’s efficiency.
BNB Greenfield approach improves performance and scalability compared to coordination-dependent systems. This is vital for attracting traditional storage users and competing with centralized cloud storage providers. By decentralizing storage and metadata tiers, BNB Greenfield achieves greater scalability, performance, and reliability.
Proof-of-Challenge in BNB Greenfield
BNB Greenfield Proof of Challenge is a robust mechanism deployed in the BNB Greenfield network to uphold the critical aspects of data management: integrity, availability, and redundancy.
Key Concepts and Mechanisms
1. Integrity: The primary storage provider must correctly store user-uploaded data objects.
2. Availability: Data segments assigned to primary and secondary storage providers must be loss-free and uncorrupted.
3. Redundancy: Erasure coding in secondary providers should enable recovery of original data stored in the primary provider.
To ensure data integrity and redundancy, metadata for objects includes checksum and redundancy setups, verified by both storage providers and users. Greenfield collaborates with storage providers to maintain data integrity and availability.
Stakeholders can initiate challenges via user requests or random events on the Greenfield blockchain, initiated by validators. After a challenge, a Challenge Verifier audits challenged data off-chain, and Challenge Verifier Consortium’s vote determines the outcome. Failed challenges result in a reduction of staked BNB tokens for corresponding storage providers, and rewards are given to participants and verifiers.
The Challenge Verifier maintains data availability, integrity, and service quality by monitoring storage providers. This mechanism penalizes and eliminates providers with poor service quality, ensuring network reliability.
The workflow of Proof-of-Challenge can be summarized as follows and depicted in the diagram below:
– Validators initiate challenges via transactions.
– Random algorithm generates challenges in each block.
– Off-chain data availability detection module initiates off-chain detection.
– Validators sign challenge votes and aggregate them.
– Aggregated votes create a challenge attestation submitted on-chain.
– Validators and submitters receive rewards, penalties are applied, and rewards are distributed.
– Cooling-off period implemented.
– The challenge process repeats if data remains unavailable.
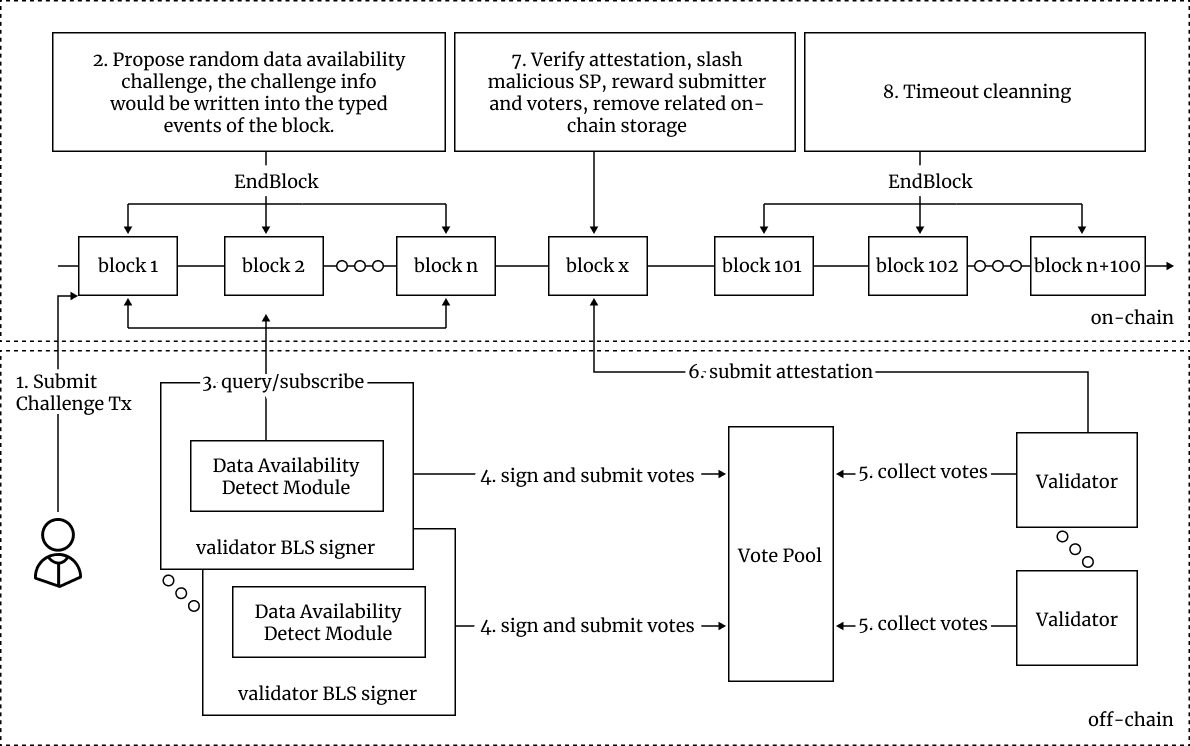
This system ensures only reliable storage providers participate, enhancing network performance and reliability. It promotes a competitive environment for providers to maintain high-quality service.
The coordination avoidance strategy deployed by BNB Greenfield shines as a prime example of how thoughtful design and strategic thinking can lead to enhanced performance, scalability, and efficiency. By sidestepping the heavy coordination overhead of traditional systems, BNB Greenfield creates an environment where data availability and reliability thrive. Through redundancy mechanisms and smart avoidance strategies, the network ensures that users’ data remains not only accessible but also free from tampering and corruption.
Future Planning
Subsequent iterations will focus on enhancing the Erasure Encoding mechanism based on real-world metrics collected from the mainnet deployment. This data will inform the optimization of configuration settings to achieve optimal reliability. Additionally, there’s an avenue for improvement by leveraging the currently dormant Primary Storage Provider copy in data reconstruction post-loss. This untapped resource holds potential to bolster overall reliability while simultaneously mitigating operational overhead.
Conclusion
BNB Greenfield is not just an addition to the giants; it’s a beacon of progress, a testament to the power of innovation, and a testament to the spirit of continuous improvement. It builds upon the wisdom of those who came before, while daring to tread new paths, forge new partnerships, and reimagine the future of decentralized storage.
As data continues to play a pivotal role in shaping industries and societies, BNB Greenfield’s innovative strides will undoubtedly resonate as a defining moment in the quest for reliable, secure, and accessible storage solutions. It is an innovation standing tall, aspiring to carry the torch forward, and leaving an indelible mark on the decentralized storage landscape.



{kind=link}