Table of Contents

Currently, all of the BNB Smart Chain (BSC) node’s data, except for historical block and state data, is stored in a single key-value database instance, with different types of data segregated by different prefixes, as shown in the table below. With the rapid increase in the amount of data, several problems are being faced:
- Inefficient performance due to mixed storage of data with different patterns.
- Decreased querying efficiency as database size grows continuously, especially in the execution process.
- Limited ability to optimize database parameters for performance of different data patterns(read and writing optimization often conflict each other).
The following table shows an overview of the current storage pattern and all data are in single database:
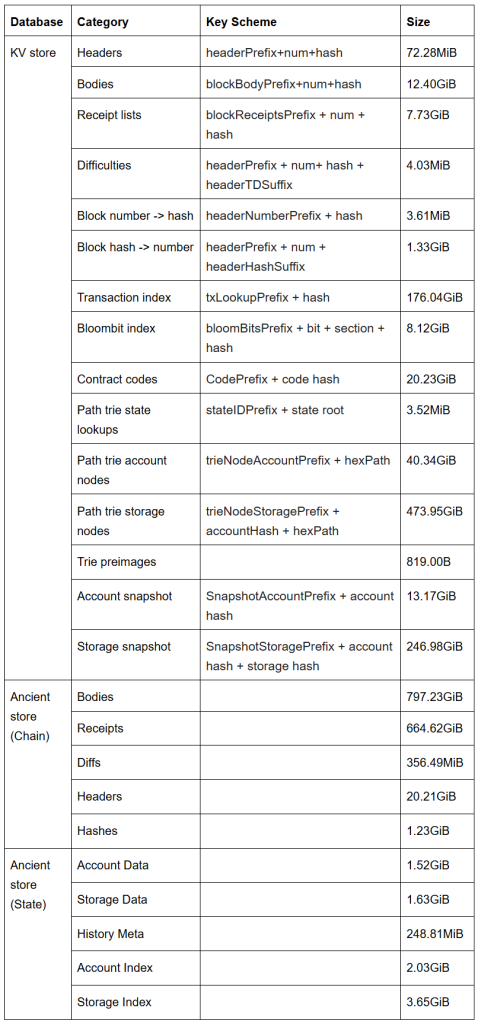
As you can see above, it is one KV store plus two Ancient stores, as in the diagram below. The single KV store handles the different data access pattern, to solve the problems mentioned above, breaking the single KV store into three, including Block, Trie, and Snapshot for BSC Geth could be a good solution as below:
Solution
Multi-Database
The blockchain data will be divided into three databases: Block Database, Trie Database, and Original Database, according to data schema and access behaviors. After database separation, the data layout obtained by db inspect is as the below table shows:
- Block DatabaseBlock-related data is stored in this store, including headers, bodies, receipts, difficulties, number-to-hash indexes, hash-to-number indexes, and historical block data.
- Trie Database All trie nodes of the current state and historical state data of nearly 9w blocks are stored here.
- Snapshot Database (read intensive database)The remaining data will be stored in this store, including snapshot, txIndex, contract code, and other metadata, etc. During block execution, the snapshot database is frequently accessed with account storage reading. We separate state data and snapshot data as one is writing intensive and the other is reading intensive, different access patterns.
Folder Structure
The folder structure for multiple databases is shown below. The original database is located within the chaindata/ folder, and new block/ and state/ folders have been introduced to store block and trie data. Additionally, there is an ancient folder for storing historical data under each of these directories.

Multi-Database
It can improve the performance, scalability, and maintainability of chain nodes by separating databases according to different data schema and access behaviors.
Block DataBase
Diving deeper into the data flow of block-related data, recent blocks data are first stored in a key-value (KV) database and then appended sequentially to the ancient database and deleted from the KV database when reaching the ancient threshold, which wastes some disk bandwidth for writing these data into the SST files and deleting them from SST files later in the database level.
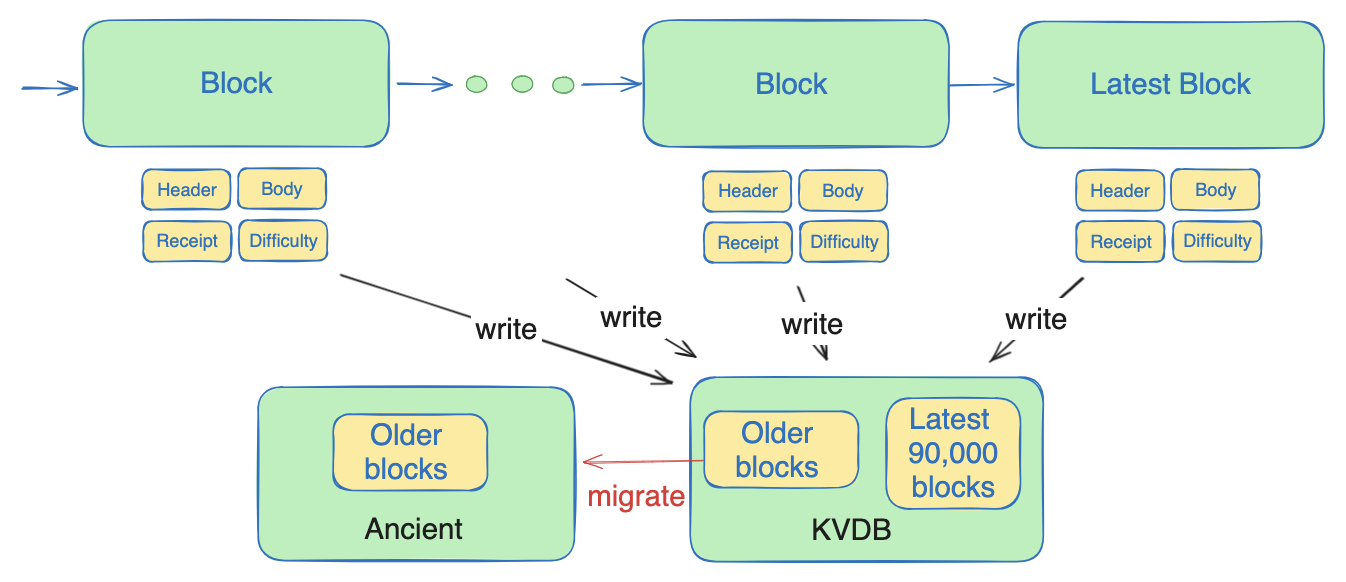
By default, Geth retains the latest 90K blocks in the key-value database, a design made for Ethereum’s “Proof-of-Work” context before The Merge. However, BNB Smart Chain now uses the Proof-of-Stake-Authority consensus mechanism with fast-finality, eliminating the need for such large data chunks in the key-value database. For BSC, it is sufficient to keep only 20-30 recent blocks before migrating them to the ancient database. To prevent data loss, a separate key-value database with write-ahead log enabled is necessary. When these blocks are migrated to the ancient store, most are stored and deleted in the memory table without flushing to the SST file.
Trie Database
The trie nodes of MPT tries constitute roughly half of the overall key-value database volume and grow rapidly. Latency to read and write trie node data significantly impacts the block execution and verification performance. Improving its read and write speed can contribute to an overall improvement in blockchain performance.
Through in-depth analysis of the data model and access behavior of Trie node data, it is evident that Trie nodes exhibit significant overwrite operations in path mode. The keys are relatively ordered along the paths. If this data is stored with other hash-keyed data in the same key-value database, it would significantly amplify the cost of database compaction, leading to senseless bandwidth consumption. If splitting the database for trie data, the independent db can process compaction with a more simplified LSM hierarchy, which would reduce the read/write latency of the entire database and improve the performance.
Snapshot Database
After separating the block and trie data, the remaining data is stored in the original database containing the account/storage snapshot, txIndex, and contract code. Due to the reduction in the amount of data, the depth of the LSM tree is reduced, thus the read/write performance of the original database will be improved.
It is worth mentioning that during the execution phase of the blockchain, there is frequent access to snapshot data. This reduction of reading latency of snapshot data will contribute significantly to overall execution performance.
Testing Result
Environment Spec
- Machine
- EC2: m6i.4xlarge
- CPU: Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz 16 core
- Mem: 64G
- SSD1: GP3 3000 IOPS, 500M/S
- SSD2: GP3 3000 IOPS, 500M/S
- Geth v1.3.10 run with PBSS+Pebble
Single Disk
Different folders for these databases, but on the same disk SSD1:
| Model | Import Block(Execution + Validation + Commit)(ms) | Execution(ms) | Validation (ms) | Commit(ms) |
| Single Database | 278 | 213 | 32.1 | 45.4 |
| Multi Database | 260 | 188 | 31.2 | 52.5 |
| Result | 6.5%↓ | 11.7%↓ | 2.8%↓ | 15.6%↑ |
Multi Disks
Trie database on SSD1 through file system softlink; the others on SSD2:
| Model | Import Block(Execution + Validation + Commit)(ms) | Execution(ms) | Validation (ms) | Commit(ms) |
| Single Database | 310 | 231 | 38.5 | 50.4 |
| Multi Database | 257 | 177 | 39.4 | 58.4 |
| Result | 17.1%↓ | 23.4%↓ | 2.3%↑ | 15.9%↑ |
It can be seen that the whole performance is improved with multi databases. And it is better when putting these databases on different disks.
Note: the validation and commit time increases because the buffer cache of the file system is mostly occupied by segments of snapshot. Some files need to swap out when validating and committing. But the overall performance has been improved by around 17%.
ETH adoption
This solution has also been contributed to the Ethereum Geth client. It has been discussed with the Geth developers and is set to proceed. Once the pull request is merged with Geth, it will become part of the Ethereum Geth feature set.
Looking Forward
With the growth of blockchain data, the demand for more refined processing of different data on BSC is becoming stronger and stronger. To get better performance, it is crucial to build a more efficient storage model for different types of data. After supporting multi databases, state data has been stored in an independent database, which makes it more feasible to build a new high performance state data engine. Together, let’s commit to making the BSC network more robust and efficient.


")
{kind=link}