Table of Contents

TL;DR:
- AI technology has rapidly evolved over the past several years, yet it faces significant challenges in the realms of data, computation, and algorithms.
- AI can organically fix these blindspots by integrating Web3 solutions.
- In Part 1, we will learn how Web3 solutions can optimize data computation and processing for AI systems.
In this blog series, we’ll focus on how Web3 technology can contribute to the increased success of AI within the current landscape, particularly in three core areas: data, computation and algorithms and how the BNB Chain ecosystem is poised to support the development of AI. We aim to explore the pressing challenges AI encounters today and examine how Web3 technologies might hold the key to unlocking solutions for these challenges.
For part one of the series, we’ll explore how BNB Chain’s multi-chain strategy and resilient infrastructure positions it as a pivotal player in the era of AI.
Additionally, we will present compelling case studies referencing innovative AI projects that are leveraging existing capabilities of Web3.
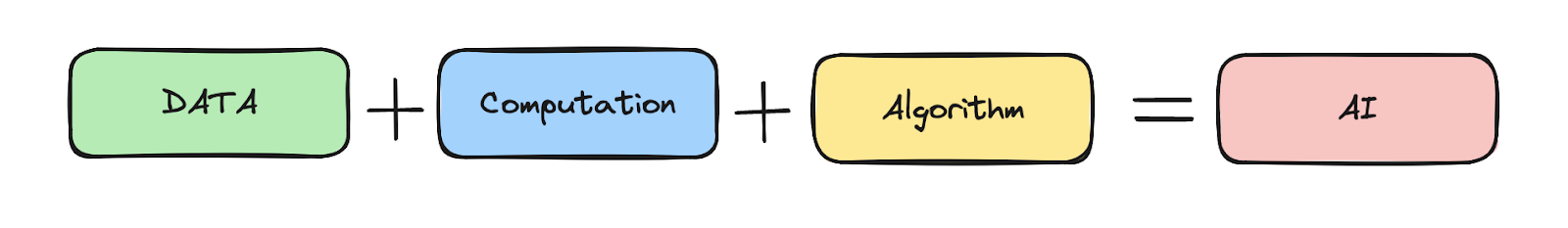
The Evolution of Artificial Intelligence
Artificial intelligence (AI) has been around for a while, with three major periods of growth linked to advancements in computing and the internet.
- First AI Boom (1950s): The Dartmouth Conference on AI in 1956 sparked the first wave of interest in AI, and early AI programs like the Logic Theorist showed promise. However, limited computing power led to unrealistic expectations and a period of decline, known as “the first AI winter.”
- Second AI Boom (1980s): Expert systems, which used decision logic to solve problems, became popular. Neural networks, inspired by the human brain, also gained traction for their ability to learn patterns. However, the limitations of these technologies and an economic bubble led to the “second AI winter.”
- Third AI Boom (Present): Deep learning, machine learning, increased computing power, and big data have fueled an AI explosion. Deep learning techniques like CNNs and RNNs have enabled AI systems to excel in image recognition, natural language processing, and machine translation.

What have we learned from AI’s history so far?
- The role of computation, big data, and the internet in AI
The advancement of AI is deeply intertwined with the development of computation, data availability, and the internet.
- Computation: Increasing computation power has enabled AI to tackle more sophisticated problems, such as medical diagnosis and autonomous vehicles.
- Data quantity: The vast amount of data now accessible has fueled the training and improvement of AI systems.
- Internet: The internet has facilitated global collaboration among AI researchers, accelerating innovation.
These factors have collectively laid the foundation for AI’s progress, and with their ongoing advancements, we can anticipate remarkable breakthroughs in the future.
More details at https://ourworldindata.org/artificial-intelligence and https://www.precisely.com/blog/data-integrity/the-importance-of-data-integrity-in-the-age-of-ai-ml.
- The Formula for AI
The formula for AI, as derived from the current literature:
Computation + Data + Algorithm = AI
This formula highlights the three fundamental components that are essential for the development and operation of AI systems:
- Computation: The processing power provided by hardware such as CPUs, GPUs, and ASICs enables AI systems to perform the complex calculations and simulations required for tasks like natural language processing, image recognition, and machine learning. Without sufficient computational power, AI systems would be unable to handle the vast amounts of data and intricate algorithms involved in AI applications.
- Data: Data serves as the fuel for AI systems. AI algorithms are trained on large datasets to identify patterns, learn relationships, and make predictions. The quality and quantity of data available to an AI system significantly impact its performance. Access to diverse and relevant data is essential for developing robust and generalizable AI models that can effectively handle real-world scenarios.
- Algorithm: Algorithms are the instructions or rules that guide AI systems in the processing of data. AI algorithms are designed to extract meaningful information from data and make decisions based on the patterns and relationships they identify. The effectiveness of an AI system is heavily dependent on the sophistication and efficiency of its algorithms. Well-designed algorithms can enable AI systems to learn from data, make accurate predictions, and adapt to changing environments.
The synergistic interplay of computation, data, and algorithms is crucial for the advancement of AI. Without any one of these elements, AI would be incomplete and incapable of achieving its full potential.
Web3’s Role in AI
Let’s delve deeper into each aspect of the AI formula and explore the potential solutions offered by Web3. In part 1, we will be solely focusing on the impact of Web3 in data computation and processing.
Web3 and Data
Data is crucial for AI’s success. Without access to vast amounts of high-quality data, AI engineers are unable to develop powerful and reliable AI systems.
Characteristics of Data Required for AI to Succeed
The type of data needed for AI to succeed depends on what it’s being used for, but some important qualities include:
Data Storage
- Structure: Data should be organized in a structured format that is easy for AI algorithms to parse and process. Structured data facilitates efficient data analysis and model training.
- Volume: The amount of data available significantly impacts the performance of AI models.
Data Quality
- Accuracy: Data should be free from errors and inconsistencies to ensure reliability.
- Completeness: Data should contain all the necessary information for AI algorithms to make informed decisions.
- Consistency: Data should be consistent across different sources and time periods to ensure trustworthiness.
Data Readiness
- Representativeness: Data should reflect the real-world conditions that the AI system will encounter in deployment.
- Relevance: Data should be relevant to the task or problem that the AI system is designed to address.
- Labeling: In supervised learning tasks, data should be properly labeled to provide the necessary information for AI algorithms to learn from.
Data Availability
- Collection: Gathering high-quality data can be time-consuming and expensive.
- Storage: Storing large amounts of data requires significant storage capacity and infrastructure.
- Privacy: AI often deals with sensitive personal information, so data privacy is important.
- Sharing: Sharing data between entities can be difficult due to privacy and legal concerns.
In summary, ensuring the availability, quality, and readiness of data is essential for the accuracy of AI systems. By addressing the challenges associated with data acquisition, storage, privacy, and sharing, organizations can empower AI to deliver valuable insights, make informed decisions, and solve real-world problems effectively.
How Can Web3 Contribute to Data Characteristics
It is common in the AI field for large volumes of high-quality data to be stored in a few centralized companies. This data is often pre-processed for AI readiness, making it valuable for developing and training AI models.
However, the data is often not publicly accessible, as it is considered a valuable asset by the companies that own it. As a result, it is unsurprising that the evolution of AI technology has primarily been driven by large technology companies in recent years, and they could produce trailblazing products based on their data.
On the other hand, it is important to note that large technology companies are not the only ones contributing to the development of AI. There is a vibrant and active community of AI researchers and developers working in academies, governments, and startups.
These researchers are making important contributions to the field, and they are helping to ensure that AI technology is developed and used in a responsible and ethical manner. But one vital problem they are facing is that it is hard to get a valuable dataset, which has high quality, satisfactory volume, easy access, and ideal storage costs. In summary, the challenges they are facing are:
- Data collection challenges: Gathering high-quality data can be time-consuming, expensive, and often requires specialized expertise and access to sensitive information.
- Data privacy concerns: Protecting sensitive personal information is paramount, and organizations must adhere to strict data privacy regulations to prevent unauthorized access or misuse.
- Data integrity: Data integrity is crucial for the performance of AI training. However, it is usually hard or costly for individuals or SMBs to access data with high integrity.
Fortunately, we have Web3 solutions that can help solve or alleviate some of those problems faced by AI researchers.
Web3, with its core principle of decentralization, potentially addresses several of the challenges associated with acquiring valuable datasets for AI development.
Decentralized Data Storage
Decentralization of data storage offers significant benefits for AI in terms of cost reduction and security.
Cost reduction
AI companies often face substantial expenses when storing large volumes of data on centralized servers managed by large tech firms or cloud service providers. These providers typically charge premium prices for data storage services, which can strain the budgets of AI companies.
Web3, on the other hand, introduces a decentralized approach to data storage, distributing data across a network of nodes rather than relying on centralized servers. This decentralized model can significantly reduce storage costs for AI companies.
There are already some projects that provide a decentralized storage network. Such as BNB Greenfield, which utilizes a peer-to-peer network to store data, eliminating the need for centralized servers. AI companies can store data on these decentralized services, reducing their reliance on expensive cloud storage services and lowering their overall storage costs.
Security
From a data security perspective, decentralized storage can help in eliminating the single point of failure of centralized storage. In centralized data storage systems, data is typically stored on a single server or a group of servers located in a single data center. This creates a single point of failure, meaning that if the server or data center goes offline, the data becomes inaccessible.
This might occur for various reasons, such as power outages, hardware failures, cyberattacks, or natural disasters.
Decentralized data storage helps to solve this problem by distributing data across multiple nodes, which can be located anywhere in the world. These nodes are interconnected and form a peer-to-peer network, meaning that they communicate directly with each other without relying on a central authority. This redundancy ensures that even if some nodes go offline, the remaining nodes can continue to operate, maintaining data availability and integrity.
Data Ownership, Quality and Integrity
In Web2, the data used in AI is often collected and owned by the centralized companies, rather than the individuals who generate the data. This can raise concerns about privacy and data ownership.
In some cases, companies may purchase data from third-party data brokers. These brokers collect data from a variety of sources. They then sell data to companies that use it to train AI models. However the users producing this data get nothing from “sharing” their data. In most cases, they may not even be aware of their data being used, which brings up ethical concerns. It may also cause issues regarding data accuracy and integrity.
In addition, the use of third-party data can lead to biased AI models. This is because the data may not be processed appropriately and may not be representative of the population, or it may be biased in favor of certain groups of people. Biased AI models can have a number of negative consequences, such as perpetuating discrimination and denying individuals access to opportunities.
Moreover, the centralization of data storage also causes weak monitoring and unexpected access control. In some cases, the data producer may not even be able to access the data they created. This may introduce a more severe issue on data integrity, correctness and abuse.
By leveraging blockchain tech, data producers own their data. They can control the data’s usage. This could involve using personal data vaults, where individuals can store and manage their data, and granting them granular control over how their data is shared with different applications and services.
Transparent Data Provenance and Tracking
The lack of transparency in data provenance and tracking on Web2 platforms is a major integrity issue. Data provenance refers to the origin and history of a piece of data, while data tracking involves following the movement and usage of data. The absence of transparency in these areas makes it difficult to verify the authenticity, reliability, and integrity of data, leading to several concerns:
- Data manipulation and misrepresentation: Without clear data provenance, it becomes difficult to identify if data has been altered or manipulated. This can lead to the spread of misinformation, inaccurate analysis, and misguided decision-making based on corrupted data.
- Privacy violations and surveillance: The lack of transparency in data tracking allows others to collect, monitor, and utilize user data without their knowledge or consent. This raises privacy concerns and can lead to targeted advertising, surveillance, and discrimination.
- Lack of accountability and auditability: Without transparent data provenance and tracking, it becomes challenging to hold companies accountable for their data practices. This hinders the ability to identify and address data misuse, discrimination, and other unethical data practices.
- Limited data sharing and collaboration: The lack of transparency makes it difficult to share and collaborate on data effectively. This can hinder research, innovation, and the development of new products and services.
Web3 technologies can play a significant role in restoring integrity and accountability in the data ecosystem. For example, blockchain technology can create an immutable record of data provenance and tracking, providing a transparent and verifiable trail of data movement.
Moreover, decentralized data governance models can empower individuals and communities to control how their data is collected, used, and shared, promoting transparency and accountability in data practices.
Data Monetization and Data Markets
In the Web2 realm, the large tech companies typically own and control user data, giving them the exclusive right to monetize it. But the data producer usually gets a low reward or even nothing from the data.
In addition, even when data producers want to monetize their data, they often face complex and time-consuming processes that involve negotiating deals with intermediaries or navigating complex monetization platforms. These barriers make it difficult for individuals to effectively monetize their data on their own.

Part of a data purchase agreement sample
Full version: https://www.contractscounsel.com/t/us/data-purchase-agreement
The centralization of data introduces limitations of the data usage, and this hinders the full potential value of data.
To address these limitations and unlock the full potential value of data, Web3 offers a decentralized approach that promotes open data access, interoperability, and user-centric data governance. By empowering individuals and communities to control their data and fostering collaboration, Web3 can enable more efficient data monetization, reduce bias, enhance data privacy and security.
End of Part One
That’s it for Part One! In Part Two, we will see further synergies between Web3 and Artificial Intelligence. In particular, we will be looking into these three pivotal areas:
- Computation optimization: We will see how Web3 technologies enhance the computational efficiency of AI systems, enabling more robust and rapid data processing.
- Framework for complex data handling: We will do an in-depth examination of the frameworks provided by Web3 that are essential for the processing of intricate datasets, thereby enhancing the capabilities of AI algorithms.
- Ecosystem for collaborative incentivization: A key focus will be the ecosystem fostered by Web3, which strategically incentivizes contributions to the AI protocol. This ecosystem not only promotes participation but also ensures equitable rewards for contributors.
Stay tuned to learn how this dynamic interplay between Web3 and AI is set to revolutionize the landscape of technological advancement.


")
{kind=link}