Table of Contents

(co-author: David, Ryan)
Overview
Layer 2 (L2) solutions are gaining more attention and becoming promising as a popular solution for Layer 1 (L1) scalability.In this series, we will focus on L2 proof solutions, specifically the fraud proof solutions. Proof systems are cryptographic mechanisms used to validate and verify transactions or computations on the blockchain. They are essential for ensuring the integrity and security of the network. By delving into the technical and mechanistic aspects of these proof systems, this series will explore various consensus mechanisms and cryptographic algorithms employed by L2 solutions to achieve their goals.
Quick overview of the Optimistic Rollup workflow
First of all, let’s quickly go through the workflow of Layer 2 with optimism as an example. Generally, the optimism works as following:
1. User Sends Transactions to L2 Sequencer
- Users initiate transactions on the Layer 2 network by sending them to the L2 sequencer. The sequencer is responsible for processing and executing these transactions.
2. Sequencer Executes Transactions and Gets New State Root
- The L2 sequencer executes the received transactions using its copy of the L2 chain. After processing the transactions, it generates a new state root. The state root represents the updated state of the Layer 2 system after executing the transactions.
3. Sequencer Sends Transactions and New State Roots to L1
- Once the sequencer has the new state root, it sends both the original transactions and the new state roots to the Layer 1 (L1) blockchain. This is typically done by invoking a smart contract on the L1 network.
4. L1 Smart Contract Waits for Challenge Period
- On the Layer 1 side, a smart contract receives the transactions and new state roots from the L2 sequencer. At this point, a time window for challenges begins.
5. Challenges (Verification) Phase
- During the challenge period, any participant on the blockchain can raise challenges against the validity of the transactions or the execution results provided by the L2 sequencer. This mechanism is crucial for ensuring the integrity and correctness of the L2 execution.
6. Finalization of Record on L1
- After the challenge period has elapsed or if challenges do not show any issues, the Layer 1 blockchain finalizes the record of the L2 execution. This means that the verified transactions and state roots are considered valid and confirmed on the L1 blockchain.
7. Penalties for Dishonest Sequencers
- In case a sequencer is proved to be dishonest or provides incorrect execution results, penalties are applied. The sequencer’s bond may be slashed as a form of punishment. Additionally, the state roots from the problematic transaction onwards will be erased and re-computed to ensure accuracy.
It’s important to note that the provided workflow is a high-level overview, and the actual implementation may have additional intricacies and details. For a more comprehensive understanding of the Optimism Layer 2 protocol, we recommend referring to the official documentation: https://community.optimism.io/docs/protocol/2-rollup-protocol.
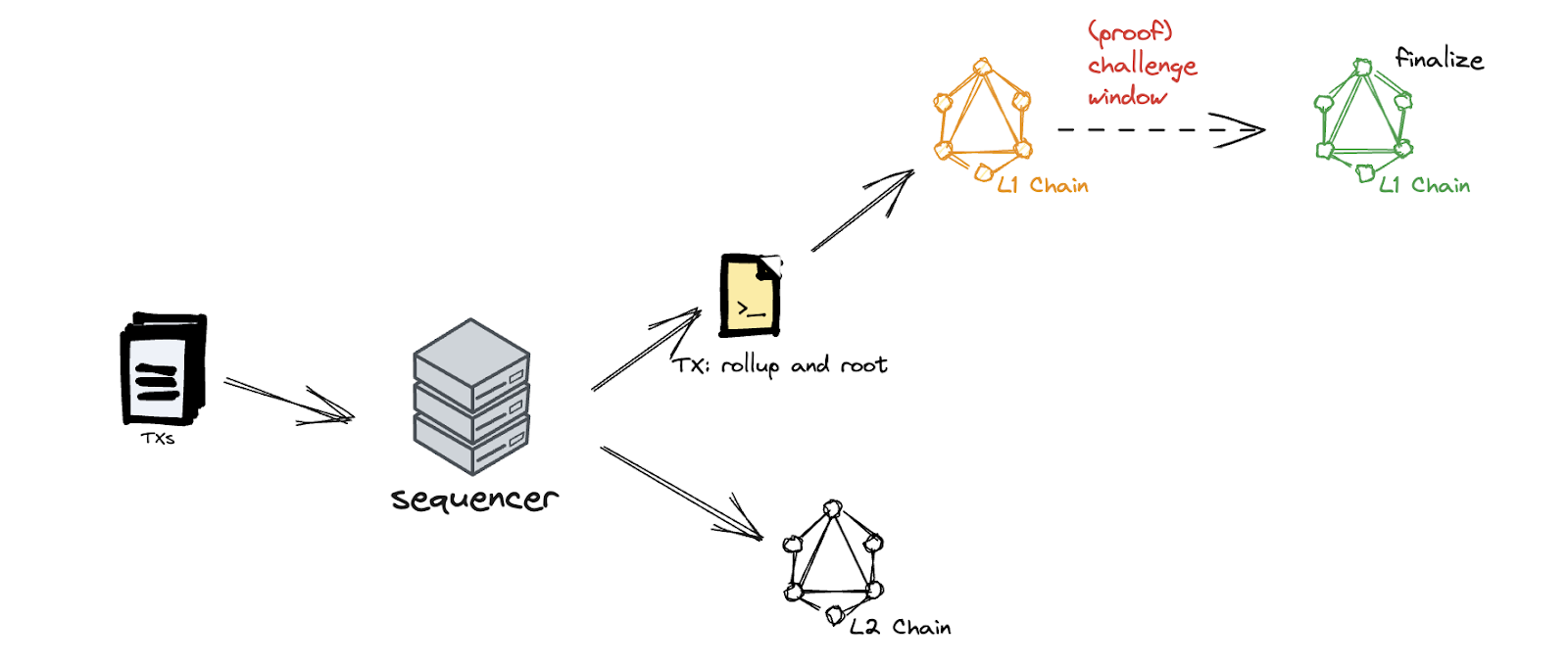
Why proving mechanism matters for Layer2 security
First of All, why is there a proving mechanism (challenging system) for the transaction of rollup and L2 states root?
The answer is to address the concern of trust, and ensure the integrity of transactions when they are submitted from L2 to L1.
For instance, Alice submits an L2 transaction to transfer 10 BNB to Bob, the actual execution of this transaction occurs on the Layer 2 network. The L1 blockchain has no clue what computation is taken on the L2 transactions unless they are explicitly recorded and submitted to L1 (usually in the form of a rollup transaction). The offloading of the computation to L2 has introduced some potential risk about trusty. If the L2 sequencer, who is responsible for submitting the rollup transactions and state roots to L1, behaves dishonestly, they could modify the transaction details and state roots to their advantage. For instance, the sequencer might transfer 9 BNB to Bob and keep 1 BNB for themselves, then submit incorrect state roots to deceive the L1.
The proving mechanism and challenging system come into play to mitigate such risks. By using cryptographic proofs, the correctness of the rollup transactions and state roots can be verified by anyone on the L1 blockchain. Validators or other participants can challenge the submitted data if they suspect any discrepancies or dishonest behavior by the sequencer.
The consensus and decentralization characteristics of the Layer 1 blockchain provide a trustless environment for this verification process. Multiple nodes on the L1 network can independently validate the proofs and state roots to ensure their accuracy. If the submitted data passes the challenges and is proven to be correct, the L1 blockchain can finalize the record of the L2 transactions, ensuring that they are considered valid and executed as intended.
This combination of cryptographic proofs and the decentralized nature of the Layer 1 blockchain creates a robust system for validating and finalizing transactions from Layer 2, enhancing the security and trustworthiness of the overall Layer 2 scaling solution.
The challenge window in Optimism is 7 days, it is where that the other players in the system (users or verifiers) verify the correctness of execution result (states root), if there is no challenge in this window or no valid challenges are raised, the execution result (state root) is considered valid and finalized on the Layer 1 blockchain. Then the users can withdraw their deposits on L1. On the other hand, if there is a challenge during this window and it is successful, the status will be dropped and the punishment of the sequencer is conducted.
By incorporating this challenge window and proof mechanism, Optimism ensures that the execution results of Layer 2 transactions are subject to scrutiny and validation by the broader network, making the system more secure and trustless. If all challenges fail to reveal any issues, users can have confidence in the validity of their transactions and securely withdraw their assets from Layer 2 to Layer 1.
Fraud Proof vs Validity Proof
As stated above, the problem the proof system is trying to solve is to guarantee that the L2 execution results (status root) of the transactions are correct and hence can be finalized on L1.
Based on how the proof system works, there are two categories of solution: fraud proof and validity proof

The validity proof is the method that when a sequencer submits the execution result (including the new state root) to Layer 1 for finalization, they also include the validity proof along with it. This proof allows anyone on the Layer 1 network to verify the correctness of the execution result without needing to re-execute the transaction on the L2 chain.
The fraud proof, also known as fault proof, operates differently from the validity proof in Layer 2 solutions. In the case of fraud proof, no explicit proof is generated at the time of execution. Instead, it assumes honesty of the sequencer, and relies on the challenge mechanism to ensure correctness guarantees.
For a quick comparison, the validity proof is efficient at verifying, verifiers just need to check the “proof” once and confirm the correctness, but the disadvantage is that it is hard to generate the proof, both in algorithm and in efficiency.A popular validity proof solution is zero knowledge proof. On the other hand, the fraud proof is efficient at execution since it doesn’t generate any proof at execution time, but the shorthand is that a specific time window must be established for participants to challenge the correctness of the L2 state, which will highly affect the finality of the L2 results.
In this article, we focus on Fraud proof and leave the validity proof in the coming articles, stay tuned.
Fraud proof solutions
As stated above, the fraud proof doesn’t require any extra operations when the transactions are executed. But it requires the challenger to submit evidence on L1 that proves correctness of the execution.
Based on how the fraud proof works and its impact on user experience, there are two kinds of fraud proof solutions: non-interactive vs interactive.
Non-interactive fraud proof introduction
An intrinsic solution is to directly re-execute all transactions on L1, which, based on L1’s native trustless and security features, guarantees the integrity and correctness of the verification result. In this way, there is no need for sequencer and challenger to interact with each other during the challenger process. So this is called non-interactive fraud proof.
To have this non-interactive fraud proof work, there must be infrastructures that support running L2 transactions on L1, and also make it possible to verify the L2’s state change on L1. It is usually not hard to have transactions submitted to L2 to re-execute on L1 as long as the L2 is EVM compatible, which makes the transactions have the same form on both L1 and L2.
But how to make the states accessed on L1 consistent as those ones on L2 is the real technical challenge.
In summary, the key of fraud proof is:
- re-execute the transaction from L2 on L1
- solve the problem of state inconsistency between L2 and L1 for verification.
To illustrate the problem of state consistency in fraud proof verification, let’s consider the example transaction you provided:
Transaction: Transfer 0.1 BNB from BankPseudo to Alice (at address 0x1234 on L2) when the transaction gets included in the block whose number is a power of 10.
Execution Flow of the Smart Contract for this Transaction:
- Get the current block number.
- Check whether the current block number is a power of 10.
- Check BankPseudo’s account balance to ensure it is greater than or equal to 0.1 BNB.
- If both conditions above are met, transfer 0.1 BNB to address 0x1234 (Alice’s account).
Now, let’s consider the scenario where this transaction is included in an optimistic rollup block (L2) and submitted to the BSC(L1) as a fraud proof for verification.
Execution on L2:
- The transaction is processed on L2 in an off-chain environment within the L2. State changes are recorded, showing that 0.1 BNB was transferred from BankPseudo to Alice’s account at address 0x1234 and the block number is 1000.
Submit to L1:
- A L1 transaction is created and submitted by L2 sequencer, which include the rollup and state root
Verify on L1:
- The verifier gets the L1 transaction, grabs the L2 transactions, re-execute the transaction on L1 and checks whether the state root matches.
However, the simple re-execution on L1 replay the transaction logic, causing problems as following
- Get the current block number. ( which is the L1 block number, not the L2)
- Check whether the current block number is a power of 10. ( it depends on the L1 block number, not the one for L2! )
- Check BankPseudo’s account balance to ensure it is greater than or equal to 0.1 BNB. (The BankPseudo’s account address is not equal to the one for L2!)
- If both conditions above are met, transfer 0.1 BNB to address 0x1234 (Alice’s account) ( 0x1234 on L1 is not guaranteed to be Alice’s account)
Here we see the problem, the state’s inconsistency between L1 and L2 actually causes the verification invalid.

The Optimism Virtual Machine (OVM v1)
To address this problem and achieve state consistency during fraud proof verification, the Optimism protocol (and other optimistic rollup solutions) incorporate several techniques and mechanisms. Some of these techniques include:
State Commitments: In optimistic rollups, L2 periodically produces state commitments that capture the current state of the system. These state commitments are cryptographic proofs of the entire L2 state and are periodically submitted to L1. By having these state commitments, L1 validators can ensure that the L2 state is valid and consistent with the claims made in the fraud proofs.
Data Availability: During fraud proof verification, the L1 validators check that the required data, including the state commitments and relevant transaction data, is available and accessible on L1. The availability of data is essential to verify the correctness of the fraud proofs and ensure consistency.
Execution Verification: The L1 validators re-execute the transactions claimed in the fraud proofs using the data from L2. However, to ensure consistency, they must do this within the context of L2, meaning they need to take into account the correct block number, contract states, and account addresses from the L2 environment.
Cross-Chain Communication: Optimistic rollup protocols often implement cross-chain communication mechanisms that allow the L1 and L2 environments to interact securely. This communication is essential for data exchange, such as obtaining L2 state commitments or passing information for fraud proof verification.
Incentive Mechanisms: To encourage honest behavior and maintain the security of the protocol, optimistic rollups typically have well-designed incentive mechanisms for validators and participants to correctly execute, challenge, and verify transactions.
Ensuring state consistency and proper execution verification is indeed a complex task, and optimistic rollup solutions like the OVM (optimism virtual machine) put significant effort into designing and implementing mechanisms to achieve it securely and efficiently.
So for OVM(v1), the core concept is to make a “container”, which makes L1 re-execution feels like running on L2. It make several infrastructure works/tools to achieve this target:
- account state preload, which is used to prepare the account states on L2 for execution on L1, so the transaction to be verified will load correct account information.
- The OVM modified the implementation of EVM bytecodes, which related to access storage, states, and other external data that may cause states different between L1 and L2.
- The OVM deployed several smart contracts on L1, and it modifies the user’s contract bytecode that related to external data accessing to invocation to the according function implementations, For example, it replace NUMBER opcode with a function call that invoke the func named ovmNumber() in pre-deployed smart contract, named OVM_ExecutionManager.
- The ovmNumber() method was implemented to guarantee that the return value is consistent with the execution result of L2. and the L2 execution information is required to be submitted with the rollup, which will be set as input of L1 OVM related smart contracts, to be used for re-execution.
- To achieve the goal of opcode change and not introduce complication to smart contract developer, the OVM make some change in the solidity compiler, which could generate OVM bytecode instead of EVM ones.
In short, the OVM(v1) solution creates a sandbox execution environment for rollup tx that re-execute on L1, by deploying several smart contracts on L1, any external data access will be handled by these smart contracts. And the smart contracts guarantee the data access on L1 is the same as the equivalent ones on L2.

So for our example mentioned above, the re-execution looks like:
- set block-number in ExecutionManager contract on L1
- start ExecutionManager and run the targeting transaction
- load contract account state so we get the related account information for BandPseudo and Alice.
- Get the current block number. (with the call to ovmNumber() in ExecutionManager)
- Check whether the current block number is a power of 10. ( it is now the return of ovmNumber())
- Check BankPseudo’s account balance to ensure it is greater than or equal to 0.1 BNB. (the BankPseudo’s account info is already loaded )
- If both conditions above are met, transfer 0.1 BNB to address 0x1234 (Alice’s account) (the 0x1234 account info on L2 is already loaded.)
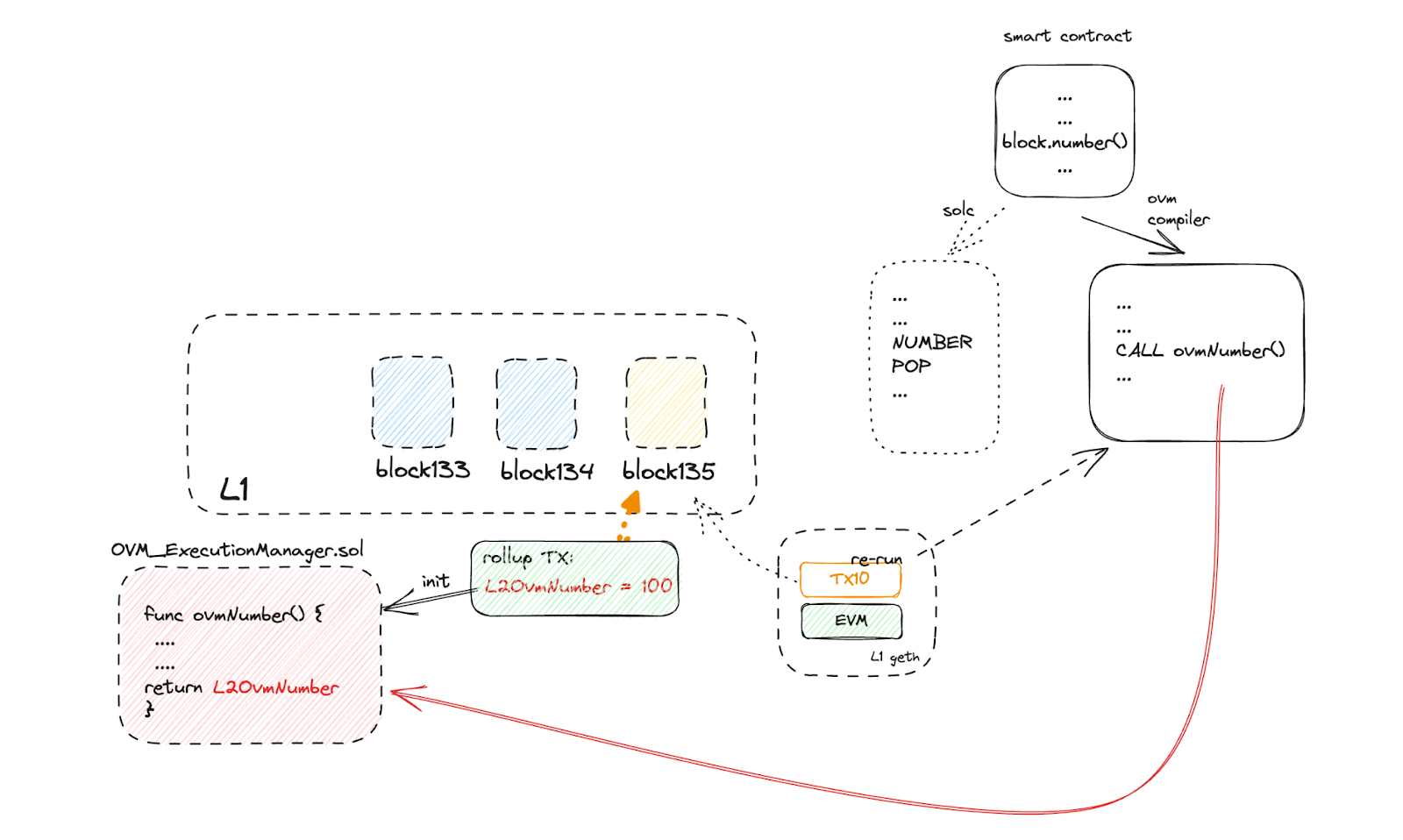
So we can see that OVM is the key component in this solution for non-interactive fraud proof.
The shorthand of OVM (v1)
Now we have seen how OVM works, let’s go further to explore what is the disadvantage of this solution.
- Complexity
Implementing the OVM requires modifications to the original contract bytecode compiler (solc) to replace state access opcodes with function calls. This additional layer of complexity may lead to challenges in developer mindset (expectation of the behavior of SLOAD, NUMBER,etc changes to function call), maintenance, and upgrades. It could also introduce potential security risks and side-channel vulnerabilities.
- Code size enlarged
The process of replacing opcodes with function calls will inevitably add extra instructions, such as pushing arguments and popping function call results. This increase in code size can result in larger contracts, which may consume more storage and increase deployment costs.
- Gas consumption
Function calls typically consume more gas compared to single opcodes. And all state access opcode are divided into several opcodes such as pushing arguments and making function calls. This means that contracts deployed on L2 will have a lower gas limit compared to their equivalent contracts on L1. This limitation can impact the scalability benefits that Layer 2 solutions aim to achieve.
- Performance
The OVM may not be fully optimized yet. Function calls, being more complex operations than direct opcodes, can introduce performance overhead and potentially lead to slower execution of smart contracts.
Due to the complexities and challenges associated with the initial version of the Optimistic Virtual Machine (OVM), the Optimism team has been working on advancing their scaling solutions towards interactive fraud proofs.
Optimism’s interactive fraud proof introduction
By definition, an interactive fraud proof is a type of fraud-proving mechanism that uses a back-and-forth protocol between two parties (defender and challenger) to verify the validity of a state transition.
In an interactive fraud proof, the challenger (verifier on L1) submits a challenge to the defender (L2 sequencer). The defender then responds to the challenge by providing additional information that supports the validity of the state transition. The challenger and defender continue to exchange information until they reach a consensus on whether or not the state transition is valid, this is called challenge game or dispute game.
Interactive fraud proofs are expected to be more efficient than traditional fraud-proving mechanisms, such as OVM(v1) fraud proofs, because they allow the two parties to focus on the specific parts of the state transition that they disagree on. This can reduce the amount of data that needs to be processed on-chain, which can be efficient at both execution and economical.
The current under-development implementation of Optimism is project Cannon, which targets to do verification with only one MIPS instruction executed on L1.
The Cannon overview
The Cannon project of Optimism aims to achieve the following targets for fraud proof:
- No Smart Contract Modification at Opcode Level
The goal is to have a smart contract that can be deployed on both Layer 1 (L1) and Layer 2 (L2) without any modifications. This ensures compatibility across different EVM (Ethereum Virtual Machine) compatible blockchains. The smart contract code remains the same, and there’s no need for a modified Solidity compiler or development tools to deploy it on different chains.
- Avoid Complexity of “EVM Running on EVM”
As the fraud proof is going to verify the execution result on L1, the direct and intrinsic idea is to implement the complete EVM in solidity and make it running on L1’s EVM, then it can accept any kind of smart contract in EVM opcode form, and verify it on L1. However, as we can easily see, it is really hard and complicated to implement an EVM thoroughly in solidity, and even if we can make it, the gas cost for execution is huge.
- Provide a Simplified Solution for L2 States Access
As described above, to guarantee the state access consistency of the fraud proof, the OVM(v1) has to “hack” all state access bytecode and initialize the data case-by-case for every transaction proving. This is complicated and limited in proving capability for sophisticated cases. And it is also not suitable for interactive fraud proof. So Cannon needed to have a mechanism that could access L2 state on L1 and also generalized enough for satisfying the requirement of different transaction execution.
- Reduce Cost for On-chain Fraud Proof
Minimizing the cost of fraud proof on-chain is crucial from an economic standpoint. Lowering the gas cost for fraud proof transactions improves the overall efficiency and cost-effectiveness of the solution.
With these goals in mind, the Cannon project introduced the following key feature:
- Unified states access solution by preimage oracle
To address the state consistency problem, Optimism implemented a mechanism called preimage. A preimage is the original data that corresponds to a specific hash value. By using pre-images and deploying the related preimageOracle contract on Layer 1, it becomes easy for Layer 1 to access Layer 2 state using the given hash value.
- Geth level replay instead of contract level
The Cannon project utilizes a geth level replay approach instead of re-executing the entire transactions on Layer 1 in the “EVM Running On EVM” environment. Geth is an abbreviation for “Go Ethereum,” which is one of the implementations of the Ethereum protocol. The geth level replay allows the system to identify potential points of suspicion that can be further verified on Layer 1.
- Reduced on-chain verification be one MIPS instruction
With geth level replay mechanism, the Cannon project optimizes the fraud proof process on Layer 1 to run verification using only a single MIPS instruction. This optimization is crucial to achieving the project’s goals of reducing on-chain costs and simplifying the verification process.
- Op-program
It serves as the bridge for accessing and generating preimage data. Additionally, it acts as the execution engine for off-chain transaction execution and identifying problematic instructions.
- The dispute game (under development)
The dispute game is a key component that involves collaboration between the defender and the challenger to identify problematic instructions. While it is still under development, its purpose is to facilitate the resolution of disputes related to fraud proofs and ensure the accuracy and reliability of the verification process.
Having all this info, now let’s dive more into the details of Cannon.
The process of Cannon
Key components
Before we deep dive into the workflow, let’s first see the key components of Optimism related with Cannon
- op-program
The op-program is a client-server implementation of preimage data access, which plays a crucial role in the fraud proof process. It serves as the initiator of the fraud proof process and is responsible for accepting commitments to all rollup inputs (Layer 1 Data) and handling disputes.
The op-program client is compiled into MIPS instructions (op-program.elf) and is used to generate the initial state of the execution (state.json) through the Cannon component using the ‘load’ command. This initial state serves as the basis for the dispute resolution, and both the defender and challenger agree on this state during the dispute game.
The op-program server, on the other hand, is used for querying and obtaining preimage data through Layer 1 (L1) and Layer 2 (L2) APIs. The server facilitates the communication between the Cannon component and the required data sources to access the preimages necessary for the fraud proof process.
- Cannon
This is the MIPS emulator that can run MIPS instructions(.elf), and it contains several components
- mipsevm
As the fraud proof is finally compiled to MIPS instruction, there has to be ways to run it both off chain for identifying the problematic instructions and on chain for challenge. For off chain, it use the Unicorn library as the emulator to run MIPS; for on chain, an MIPS interpreter is developed in solidity and deployed, in both case it need a loader to load the MIPS binary (elf file) and prepare the data before execute, and this is what mipsevm takes the role.
- on chain smart contracts
MIPS.sol
This is the core implementation of on chain MIPS instruction interpreter, it accepts the binary of proof (MIPS instructions) and executes, whenever there is state access, it is designed to trigger an read(4003)/write(4004) system call, which invokes external preimageOrace.sol to get related data.
PreimageOracle.sol
This is the contract that helps to serve the preimage request from MIPS.sol.
Workflow
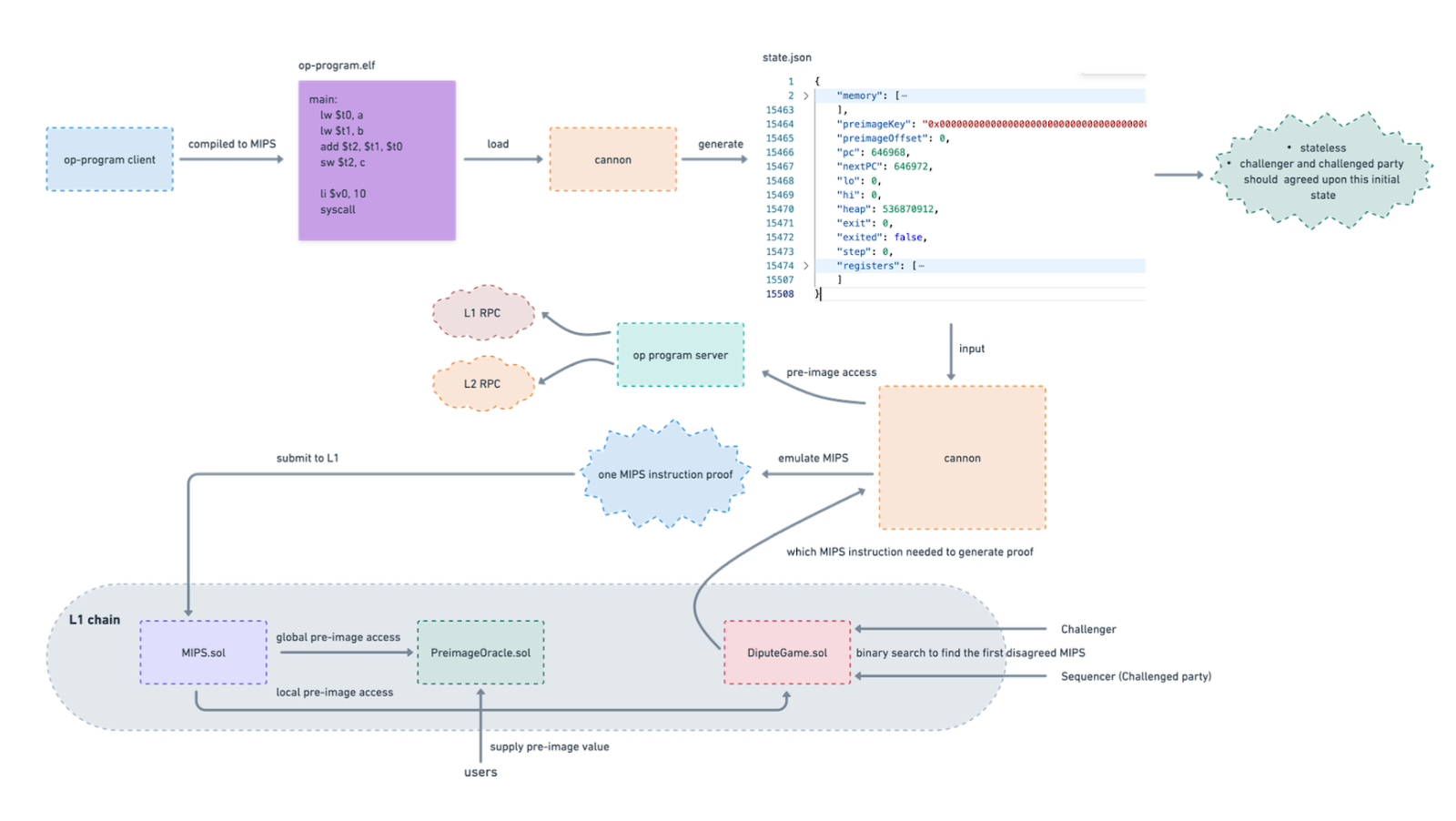
- The MIPS backed op-program client (compiled to op-program.elf) is loaded to the cannon MIPS emulator, which generate the initial status of the fraud proof process, this can be treated as the start point of the challenge game, at which both the defender and challenger agrees on the init status. notice that there is status.json generated, the content in the json file indicates the preimage key and offset used ( as the init state not access any states, it is 0), the current program counter (an offset specifies which MIPS instruction is executing), the next program counter ( offset of the next instruction to be executed), heap is the heap size and by default is 0x20000000 (536870912).
- Having generated the init state.json, we need to figure out the way to execute from this start point and run given steps in mipsevm (assume that we already know the problematic state happens after n steps execution), then generate the fraud proof for online use.
During the execution, it is usually very likely that the program may read/write L2 states, and we need to record the related access and save the preimage if it is required for the problematic instruction, this functionality is achieved by the op-program server .
So the logic is that we use cannon for step running, and cannon communicate with an op-program server for state accessing (through preimage).
- Having seen how state initialization and step run works, let now take a look at how dispute game works, although some of the implementation is still WIP, we can make reasonable inference based on what we have known now. First let’s have a quick overview on the dispute game logic flow.
- As stated above, the dispute game kicks off when challengers find the L2 rollup state change run by themselves is different from the one recorded on L1, so they submit a transaction that requires the dispute game.
- The dispute game requires both defender (sequencer) and challenger (verifier) to take part and identify the first instruction that makes the states change differently from each side.
- Then the candidate instruction and the related materials such as preimage offsets and keys are prepared and submitted to the MIPS.sol smart contract to verify the execution result and decide the winner.
Now the details:
- The dispute game smart contract (in-development, namely DisputeGame.sol), requires the defender and challenger to start from an agreed point of the program, and using the binary search to identify the instruction which generates different states. Be aware that this is interactive and the execution is not necessarily to be conducted on chain. A reasonable execution scenario of the dispute game could be following:
a. (challenger) submit a state and execution point of the transaction, wait for defender’s agreement of the states and the execution point.
b. (defender) agree on the execution point and states, the dispute game continue
c. (challenger) submit a new execution point and states (using binary search for instance), wait again for the definder’s agreement
d. alternatively iterate the game until there is disagreement for defender and challenger.
e. prepare the fraud proof materials, which contain the state’s changes and execution point.
f. submit the proof to MIPS.sol for on chain verification
2. on chain MIPS interpreter (MIPS.sol)
This is the on chain MIPS instruction interpreter running in EVM, it accepts the proof materials, then executes the instruction, and verifies the states change.When there is state access required during the execution, it calls functions in PreimageOracle.sol to access the data.
3. on chain preimage processing(PreimageOracle.sol)
This is the on-chain mechanism for L2 status access processing; it actually requires the user to supply the preimage data which will be accessed when the proof is executed by MIPS.sol. Be aware that there is no extra guarantee of the correctness of the submitted preimage because the [hash] -> [preimage] correctness is guaranteed by the hash algorithm and the hash is provided from the proof material, which already has correctness guaranteed by dispute game.
Now that we have surfed all the key features of the optimism’s implementation of interactive fraud proof – Cannon. As we can see it does reduce the on chain process of fraud proof, which could help reduce the cost of re-execution. We are quite sure that this article can not cover all details of the Cannon, and hopefully it could help you understand the mechanism and implementation of the key points of Optimism’s latest interactive fraud proof solution.
Optimism’s interactive fraud proof challenges
Having all these been written, here we still want to share more of our understanding of the Cannon design, and what are the challenges we think for current solutions
- The choice of MIPS instruction set
The first time I read the Cannon design, the first question I got is why it chose MIPS instruction set as the fraud proof execution, not the popular IR such as wasm or modern low level instruction set such as x86 or arm32. After researching, it seems the MIPS is chosen by following reason:
- Natively supported by golang
Unlike wasm, the MIPS instruction set is native supported by golang compiler, which means the most popular EVM implementation – geth is easily compiled to MIPS as target binary.
Please note that there are also proposals and implementations for using wasm as an execution engine, it is still not easy for golang programs to be fully compiled to wasm. But as wasm is becoming more and more mature nowadays, it is no doubt that wasm can be a good candidate here in near future.
And there is also a proposal of using RSIC V, which is mainly for zero-knowledge based fraud proof, we will deep dive into it in another article.
- Easy-writing interpreter
The MIPS instruction set, unlike x86 and arm32, the MIPS instructions are simple, we can see that it only takes ~400 lines of code for implementing a MIPS interpreter with solidity (refer to the official repo https://github.com/ethereum-optimism/optimism/blob/0ecda15d04ddfdb41b4f2fad95e2e9e97b50b53d/packages/contracts-bedrock/contracts/cannon/MIPS.sol#L571). Which not only makes it easy for maintaining but also provides lower security risks.
- The potential problem of hacking golang
From the implementation of mipsevm, we can see that Cannon patched several golang runtime functions, it is mainly for simplicity and to remove non deterministic behavior. One of the obvious changes is that Cannon disables golang GC, which may cause OOM error in some memory intensive scenarios.
Although we think disabling GC may not be a problem at present since the whole fraud proof works on transactions, and there is no such scenario that is memory intensive, it leaves the potential risk for failing to verify some transactions in the future, when the smart contract logic becomes more sophisticated.
- Fraud timing window
The most significant drawback is the timing window, which is an indispensable module for fraud proof systems. The target of this timing window is designed as a period for verifiers to verify the proof and challenge game if necessary, and it is also needed for states to be retrieved back if the proof is proved to be dishonest. The current commonly used value of timing windows is 7 days for most fraud proof based L2 solutions. This means that users who deposit tokens to use L2 have to wait for 7 days before they can withdraw, which is much too long compared to L1 transactions’ finalized time (several seconds on average).
Then, why is it 7 days for the timing window? Although there no exact explanation of the reasons why 7 days is chosen, our investigation show the following considerations may be reasonable factors:
- The verification duration
It is hard to decide when and how long it will take for a verifier to verify the rollup transaction and trigger the challenge.
2. The dispute game duration
As the dispute game is interactive, it can not be determined how efficiently the defender and challenger could react to each other to finish the game.
3. The L1 worst-case congestion duration
As we know, all rollups and challenges are submitted to L1 in the form of a transaction, so if the L1 is getting congested, the transaction can not be confirmed in an ideal time. And if that happened, it means all rollup related operations can not work as expected in accepted time. So the timing window should be conservative considering this worst case. (Till now the worst congestion duration of ethereum is ~24 hour in history, happened in May 2021, so that the 7 day should be fully enough)
4. Incentive and penalties handling, and the states retrieve time for dishonest rollup
If the proof is proved to be dishonest, it takes time for incentive and penalties. And to retrieve the states, which definitely takes time. Be aware that although the retrieval itself may not be too slow to drop out of the timing window, it is the last step in the fraud proof process, therefore the timing window should consider the whole process combined together.
- Security
Although the Cannon’s interactive fraud proof system is designed and implemented to improve the security by reducing the attack surface of L1 smart contracts, we think there are still some factors that need to be considered for security.
- The security of the L1 smart contracts
As the Cannon’s result is highly dependent on the execution result of the on-chain MIPS interpreter contracts (MIPS.sol), its security is the key to the success of the fraud proof system. So any breaches on it should be highly valued and processed in high priority.
- The security of the off chain components
This is where most of the challenger makes judgment, so if there are any critical bugs that could affect the execution result of the transaction, it may cause the challenger to submit the dispute game wrongly, which not only affect the rollup finalization time, but also waste the gas spent for fraud proof.
Alternative solutions
At the same time the interactive fraud proof is developing, the community also gets several proposals of zk-based fraud proof, which is designed to reduce or eliminate the interaction phase of the fraud proof. The design is that when there is a challenge game needed, the defender will generate the zk proof of the transaction execution, and the L1 verifier would verify the proof’s correctness and make the decision.
Please note that it is not exactly like the zk based validity proof, which requires the zk proof to be generated at the transaction execution stage and verified automatically on L1 when the rollup transaction is submitted.
At the time of this article’s writing, the optimism community just made a decision on adopting the RISC based ZK solution, we are planning to have another article to describe what solutions have been proposed in near future.
L2 Proof of opBNB
As an important L2 blockchain implementation based on Optimism’s OP Stack, opBNB are working actively on investigating the whole technical details of fraud proof technology and working on (and surely not limited to) the following aspects on Functionality
- Improving efficiency of fraud proof off-chain infrastructure
As analyzed, the off-chain infrastructure components play an important role in the life cycle of fraud proof systems. It not only contains the MIPS emulator, but also the stripped geth implementation, the EVM, the pre-image data preparation, and the step function implementation. Therefore we believe that the quality and efficiency of these key components is vital and worth the effort of enhancing.
- Optimize the challenge timing window
This is one of the most important problems that determines the effectiveness of the L2 fraud proof. As the token can not be withdrawn from L2 until the timing window is over, it introduces a negative impact on user experience. Nonetheless, the current 7 days setting for the time window is not perfect, especially when users need to transfer tokens between L2 to L1 frequently for their business requirements. Therefore there is enough reason to shorten the timing window, and we are now exploring solutions to achieve this target.
- Help improve and solid the related on-chain contracts
The on-chain smart contract of fraud proof is the key for challenging the result’s correctness, so any kind of breach or side channel in the contract could potentially lead to incorrect execution. We also volunteered to be the security enhancer of this key component.
- Explore alternative business-driven solutions
We would also like to research alternative fraud proof solutions, such as interactive with different instruction sets like wasm, RISC V etc; more efficient dispute game solution; zero-knowledge based proof solutions etc.
Although All these research and solutions will take opBNB’s business requirement as a basis, we will not only focus on the opBNB itself, but also try to make contributions to Optimism’s community as much as possible to grow together with the community.
Conclusion
This article has tried to explain the evolution of the L2’s fraud proof system and Optimism’s latest interactive fraud proof solution – project Cannon. We analyzed the details of OVM(v1) design, and dived into the design and implementation of Cannon. As opBNB keeps evolving, the opBNB is trying to help improve and optimize in the detail of the opBNB’s fraud proof system, and we are planning to share more details of the process and innovation of opBNB’s solutions, stay tuned.
References
- Optimisic Rollups. https://ethereum.org/en/developers/docs/scaling/optimistic-rollups
- Cannon documents. https://github.com/ethereum-optimism/optimism/tree/develop/cannon/docs
- OVM Deep Dive.
https://medium.com/ethereum-optimism/ovm-deep-dive-a300d1085f52
- How does Optimism’s Rollup really work?
- Thunder and Lightning – How the Cannon works https://typefully.com/norswap/thunder-and-lightning-how-the-cannon-works-GyqpjNs
- Optimism Bedrock – Technical insights and implementation Details
https://gamma.app/public/Optimism-Bedrock-1vcsrk7e5q1lcqu?mode=doc
- Fraud proofs and Virtual machines
https://medium.com/@cpbuckland88/fraud-proofs-and-virtual-machines-2826a3412099
- Dispute Games



{kind=link}