Table of Contents

Parallel EVM (Ethereum Virtual Machine) is an advanced approach to optimizing blockchain performance by allowing multiple transactions to be processed simultaneously. In traditional EVM, transactions are executed sequentially, which can lead to performance bottlenecks, especially under heavy network load.
Parallel EVM addresses this limitation by identifying independent transactions that do not conflict with each other and executing them in parallel. This parallel execution significantly enhances transaction throughput, reduces latency, and improves the overall scalability of blockchain networks, making them more efficient and capable of handling a higher volume of transactions.
Performance Bottleneck of Parallel EVM
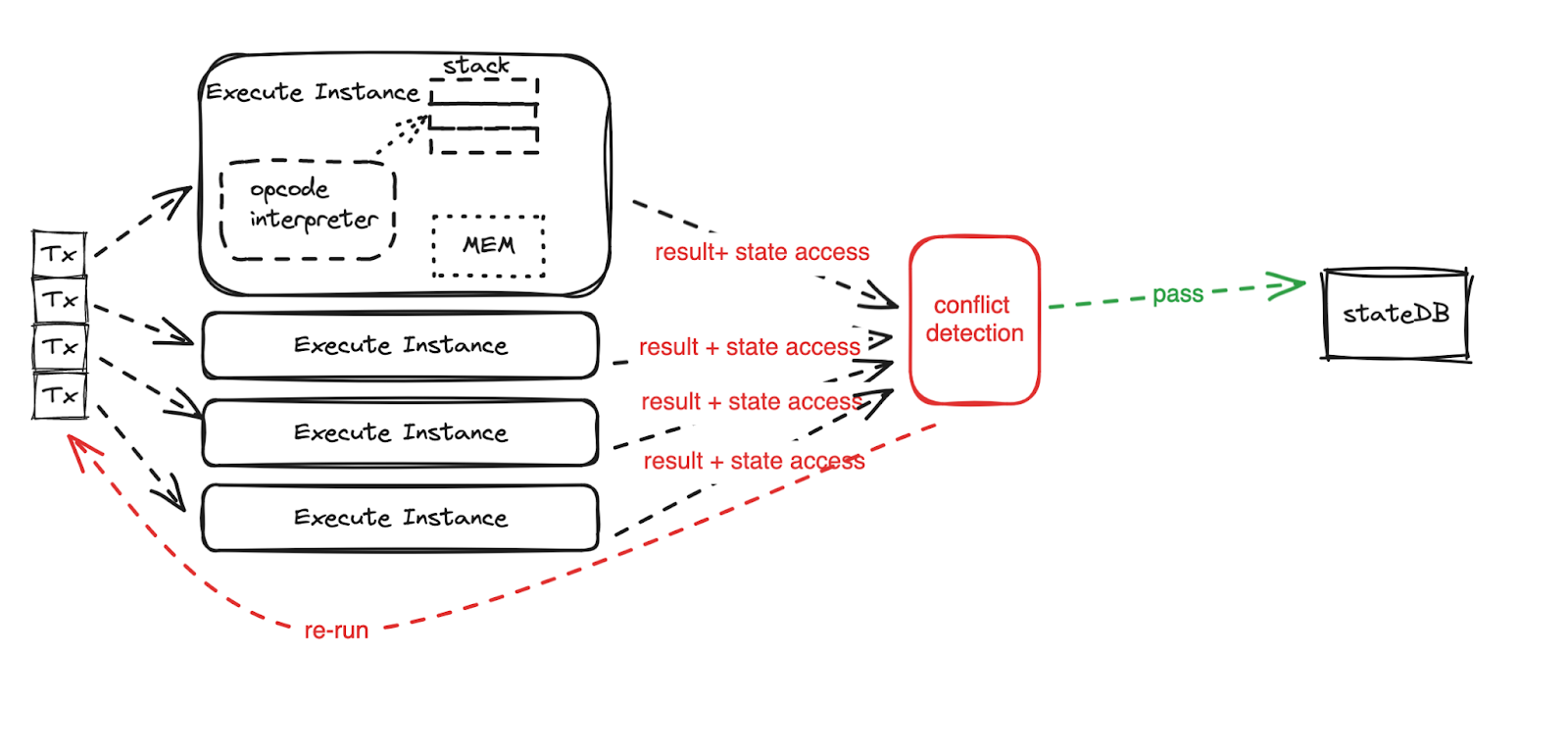
Traditional parallel processors often attempt to execute transactions optimistically in parallel, assuming no conflicts will arise. However, when conflicts between transactions are detected, the system must roll back and re-execute those transactions to ensure accurate results.
This rollback process consumes considerable computing resources, leading to inefficiencies. In some cases, the overhead from detecting and resolving conflicts can cause the system to perform worse than if the transactions were processed sequentially, negating the benefits of parallel execution.
For example, in one block, the dependencies of transactions may look like this:
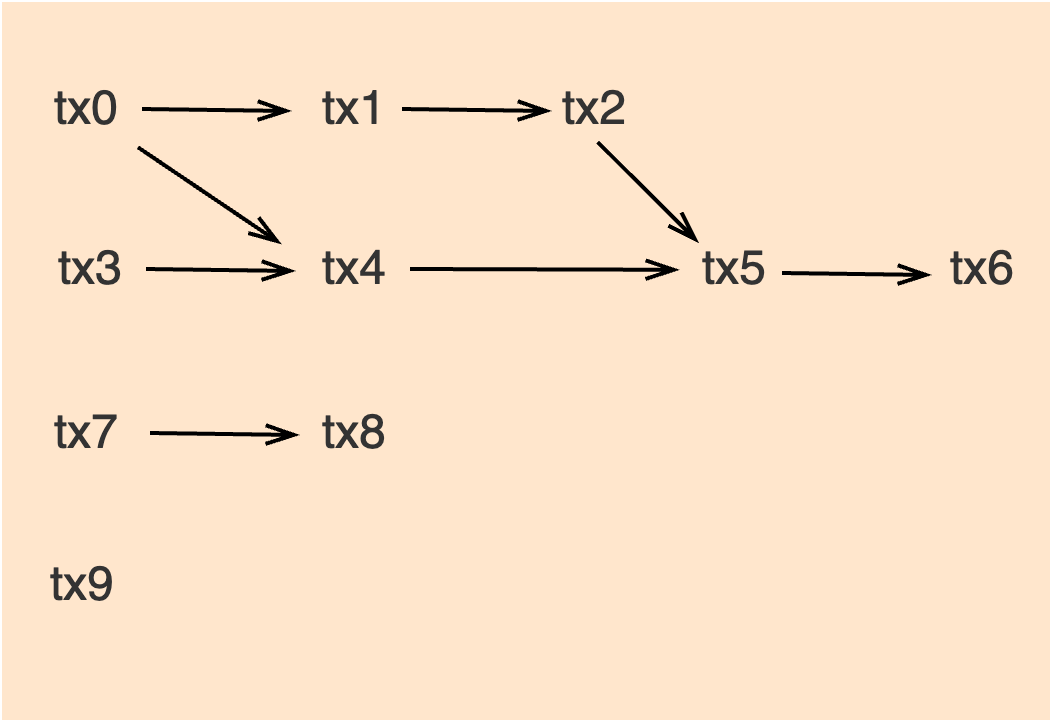
When parallel instances execute transactions, the following result will happen, and there will be lots of transaction execution rerun and computing resource waste.

Dependency Hint Introduction
To maximize block execution performance, transactions must run in parallel, fully utilizing computing and I/O resources. Knowing transaction dependencies enables a clear parallel execution path.
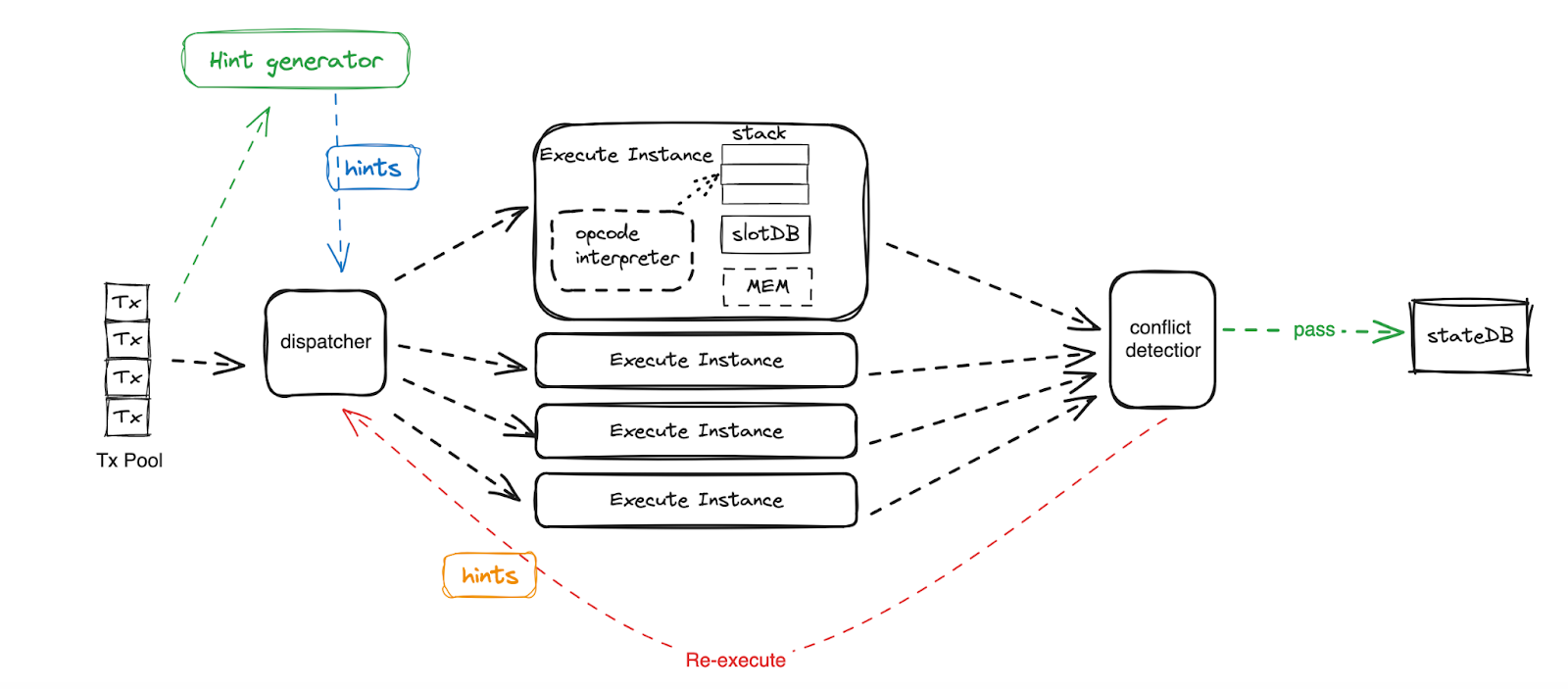
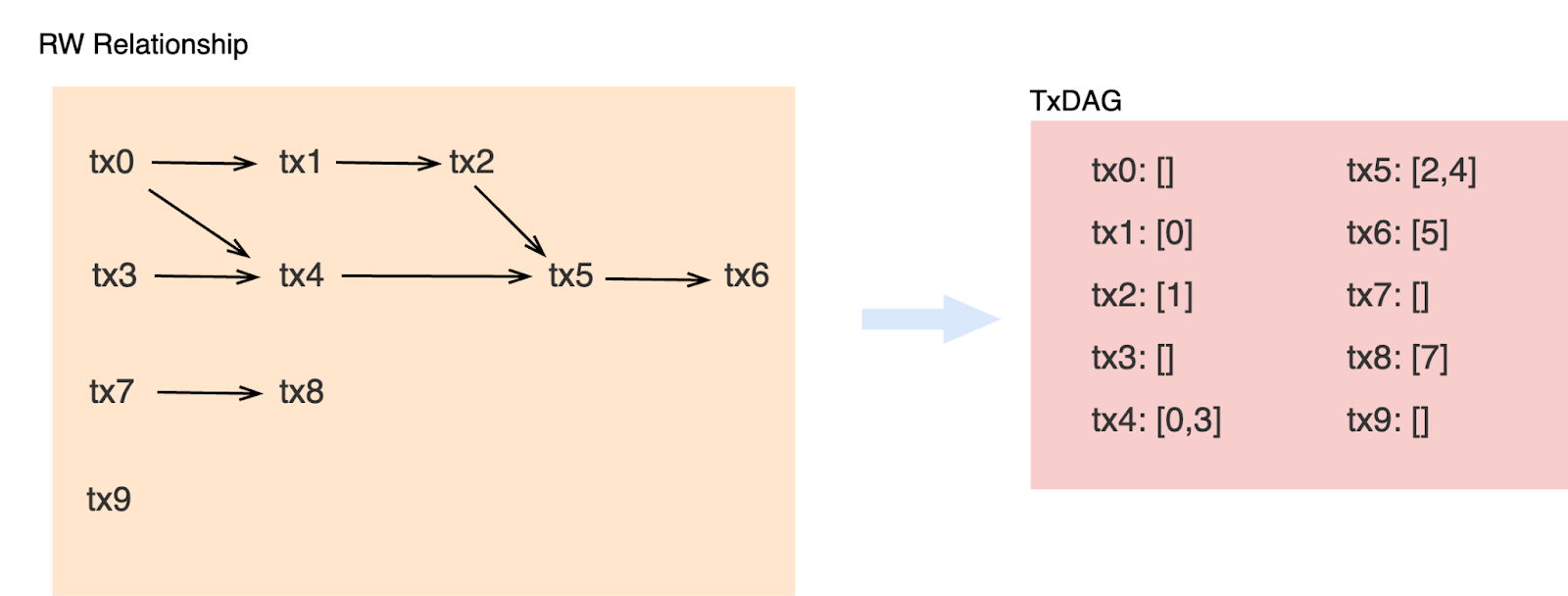
Dependency Graph TxDAG
Dependency Graph TxDAG (Transaction Directed Acyclic Graph) is an interesting approach designed to enhance blockchain performance by structuring transaction processing based on dependencies.
Unlike traditional methods that process transactions sequentially or optimistically in parallel, TxDAG builds a dependency graph to determine which transactions can be executed simultaneously without conflicts.
Mapping dependencies in advance allows non-conflicting transactions to run parallelly, avoiding costly re-execution. This boosts throughput, optimizes resource use, and enhances scalability for blockchain networks like BSC.
How is TxDAG Generated
Proposer Builder Separation(PBS) and Block Production
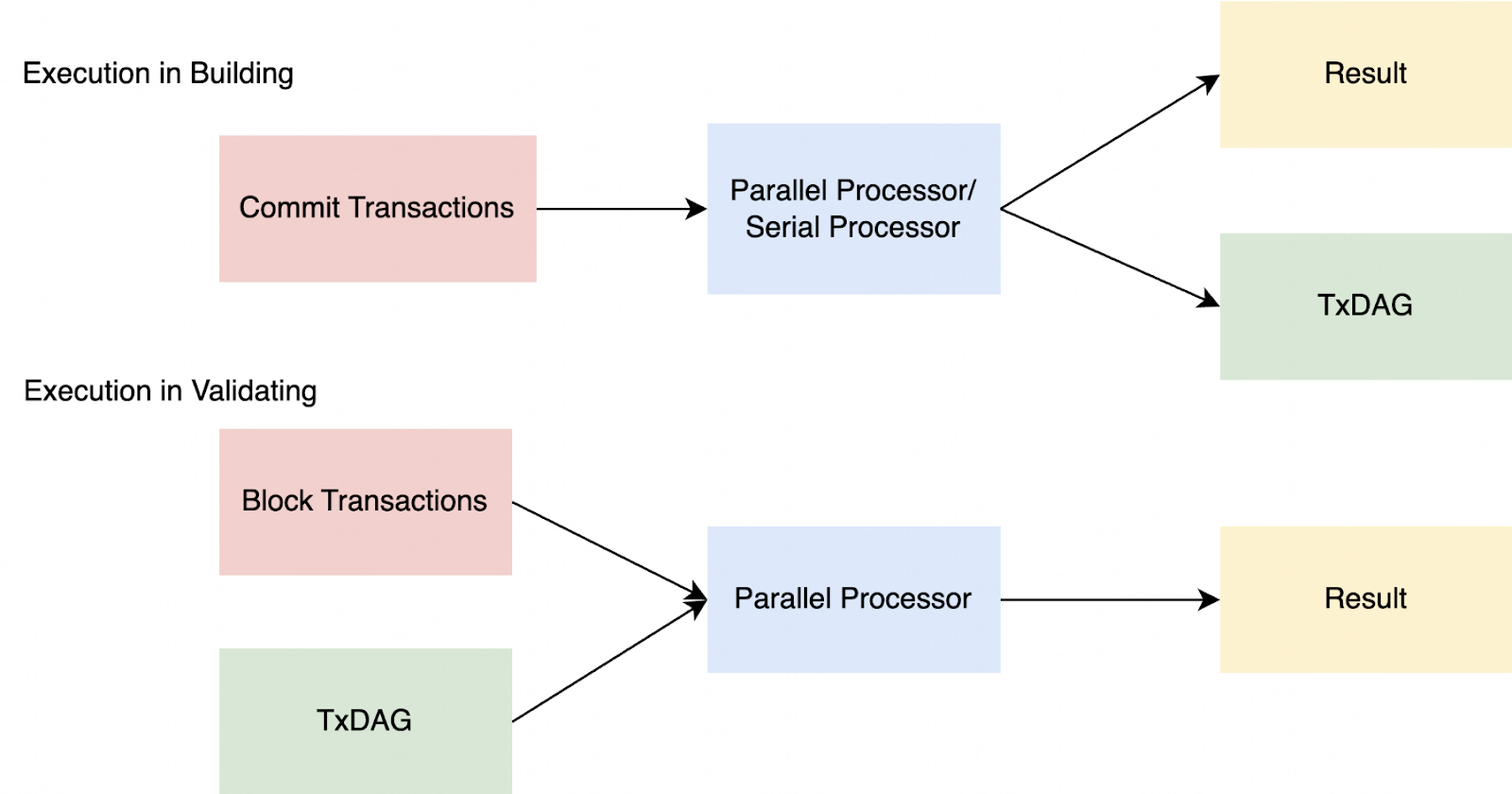
BSC has introduced the PBS and the builder can generate the TxDAG through read-write sets after the builder pre-execute transactions. After the TxDAG is generated, it can be included in the unsealed block bid and forward to proposers(validators) to validate. Below is a simplified diagram to explain the process.
First, pre-execution by builders, and currently, the TxDAG is generated in the mining process by builders.
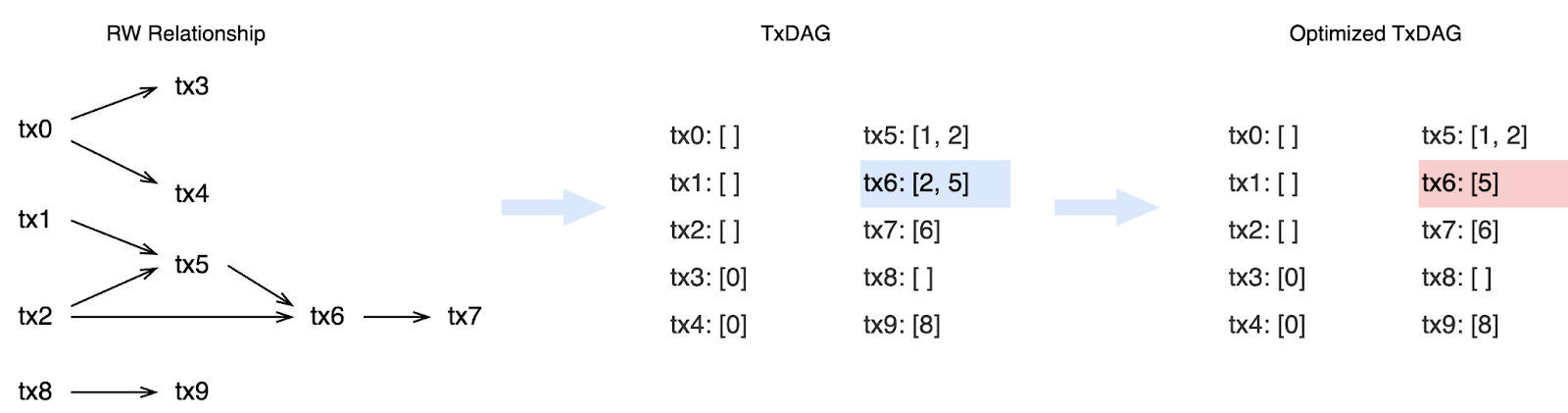
TxDAG compression
There is also a potential TxDAG “compression algorithm” to further optimize the size. For the DAG describing the dependencies, some are redundant because it only needs to ensure that the final execution path is consistent.
How TxDAG is forwarded
To pass TxDAG data from builders to proposers for validation and block sealing, three methods are possible:
- Reuse the Extra field in the block header to store TxDAG data. This is simple but constrained by the header’s size limit.
- Add a new field in the block body, with the TxDAG hash in the header for verification. While more robust, it requires a hardfork to update consensus logic and an incentive-slashing mechanism for builders.
- Embed TxDAG data in a transaction using system or gasless transactions. This avoids changes to consensus logic but lacks incentives for builders to generate the TxDAG.
Each method has trade-offs between complexity, scalability, and builder incentives.
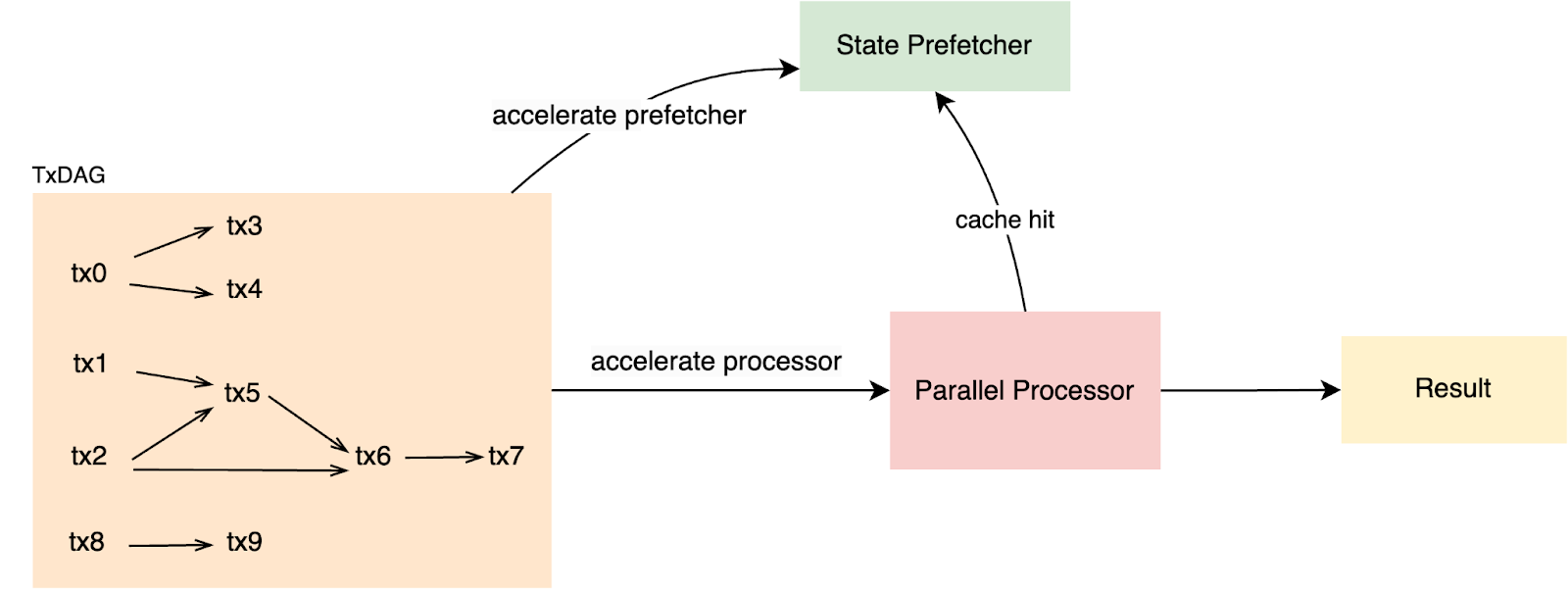
TxDAG speed up the validation process
The simplest way to accelerate block validation with TxDAG is by integrating parallel processors. Typically, parallel processors execute transactions optimistically, but with TxDAG, they can follow the optimal parallel path for the entire block while quickly identifying invalid DAGs.
Additionally, TxDAG can enhance state prefetcher scenarios (introduced in BSC performance optimization) by preloading states through parallel prefetchers, significantly improving the processor’s cache hit rate.
Performance Testing in lab
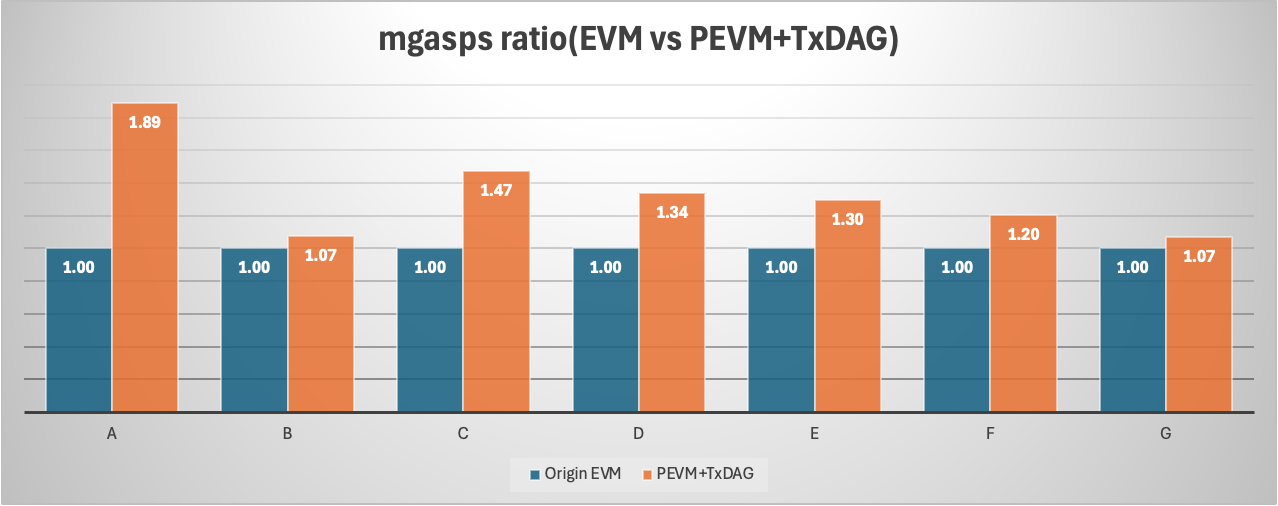
Introducing TxDAG resulted in an 88% performance improvement under fully conflict-free transactions. As transaction conflicts were gradually introduced, even with over 95% of transactions having conflicts, there was still a 7% performance gain. With simulated mainnet data showing 30%-70% transaction conflicts, the actual performance improvement averaged around 30%. Below are the detailed performance test results.
| Scenario | Description | Average Mega GasPer Second(origin EVM) | Average Mega GasPer Second(PEVM+TxDAG) | Performance Gain | Data Description |
| A | Internal test chain blocks with 250k accounts transfer to another 250k account | 107 | 202 | 88% | conflict: 0%Txs/Block: Avg 3103 |
| B | Internal test chain blocks with 250k accounts transfer to 1 fixed account | 201 | 216 | 7% | conflict: 95%Txs/Block: Avg 3644 |
| C | Internal test chain blocks contain random selected txs with a mix of smart contract and native transfer | 155 | 228 | 47% | conflict: 81%Txs/Block: Avg:1356 |
| D | Internal testchain with blocks contains 10k txs that transfer from 10k accounts to 10k accounts that randomly pick from same account set | 515 | 675 | 31% | conflict: 75%Txs:Txs/Block:10016 |
| E | Internal testchain with blocks contains 10k txs that transfer from 10k accounts to 10k accounts that randomly pick from different account set | 362 | 470 | 30% | conflict: 34%Txs/Block: Avg:9571 |
| opBNB mainnet | |||||
| F | opBNB mainnet block range from # 9m-9.3m | 9.3 | 11.2 | 20% | conflict: ~12% , Txs/Block: Avg: 25 |
| G | opBNB mainnet block range from # 11.93m-12.1m, mostly inscription txs | 57 | 61.1 | 7% | conflict: ~60%Txs/Block: avg: 790 |
Testing data summary
Call for Community Discussion
BNB Chain is among the pioneering blockchains to introduce TxDAG, enhancing Parallel EVM performance based on valuable community feedback.
TxDAG Forward Mechanism
As noted, deciding how to forward TxDAG from builder to proposer is crucial, along with introducing incentive mechanisms to ensure honest TxDAG generation. The table below summarizes the differences among the three proposed methods.
| Option | Pros | Cons |
| Reuse the Extra field in the block header and fill it with the TxDAG data | Easy to implement | TxDAG size limit, and require hardfork |
| Add a new field in the block body and include the TxDAG hash in the header for verification | No size limit | Require hardfork |
| Use transactions to carry the TxDAG data within the Calldata. | No size limit, No need hardfork | No incentives to encourage builders to generate TxDAG |
TxDAG Incentive Mechanism
TxDAG is optional for decentralized builders, but it carries the risk of malicious DAGs, which fall into two categories: Wrong DAG and Bad DAG.
- Wrong DAG includes incorrect TxIndex, violations of preset orders, or circular dependencies. These issues can be quickly detected during verification, and the block will be rejected.
- Bad DAG is more subtle, providing incorrect dependencies that reduce parallelism or create conflicts.
To mitigate these risks, a builder punishment mechanism is essential to ensure compliance and maintain system integrity.
For details, please refer to BEP-396.
Future Work
The current TxDAG based PEVM implementation is just the first step of PEVM for BNB Chain, and the following advanced optimizations are in BNB Chain roadmap:
Advanced transaction scheduler
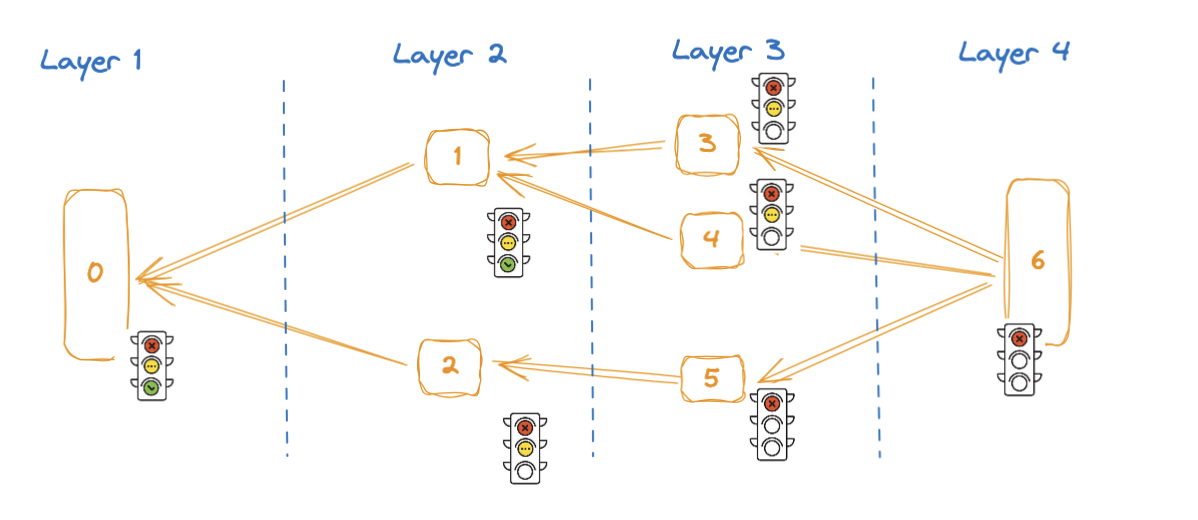
The current TxDAG-based scheduler is simple and efficient for layer-level parallel execution. However, further optimization opportunities exist, such as reducing the scheduling granularity from layers to individual transactions to enhance parallelism.
For example, in a layer-based scheduler, Tx3 and Tx4 must wait until both Tx1 and Tx2 in Layer 1 are completed before executing in Layer 2. This delay is unnecessary since Tx3 has no dependencies on Tx2, limiting scalability.
With transaction-based scheduling, the scheduler can execute Tx3 and Tx4 as soon as Tx1 is complete, without waiting for the entire Layer 1 to finish.
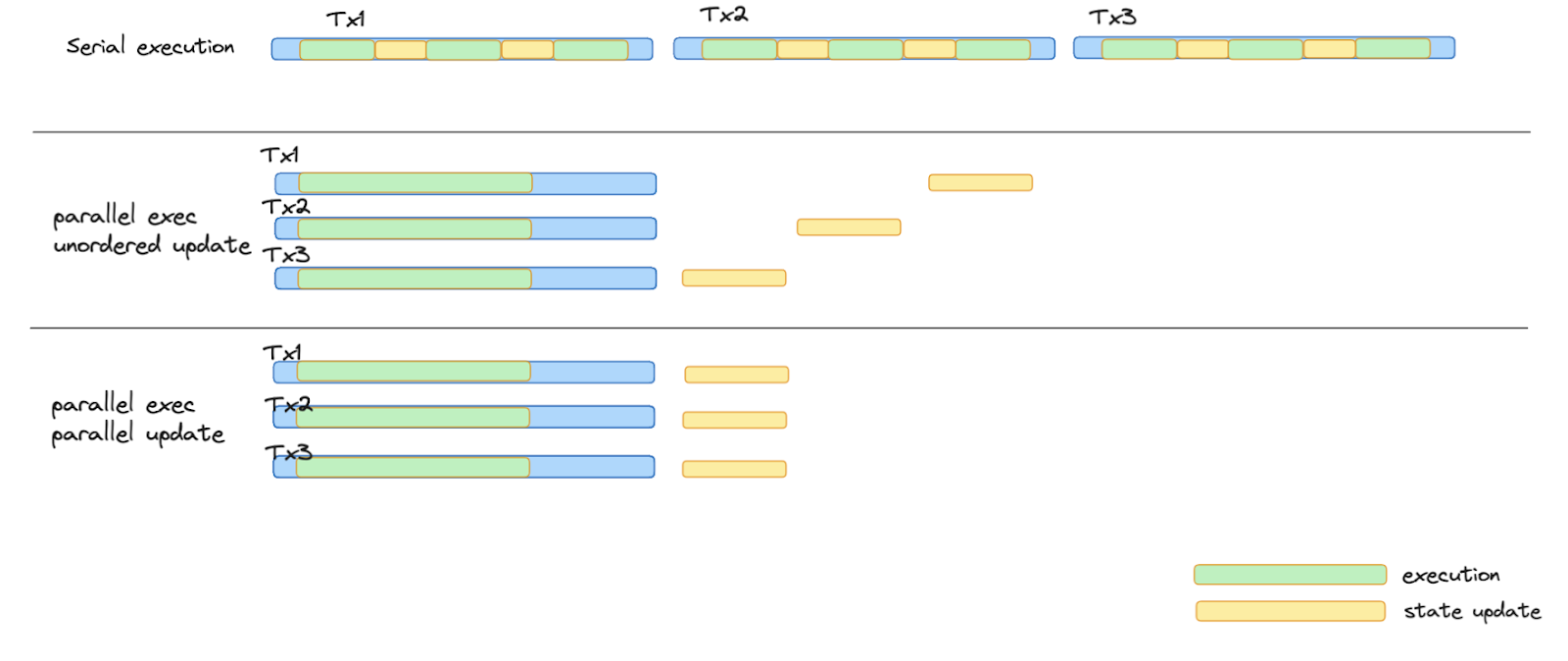
Parallel stateDB
Currently, BNB Chain has implemented an unordered stateDB, allowing the state change of Tx5 to be updated before Tx3, as both transactions are in the same layer. This optimization demonstrates significant improvement over in-order merging.
However, the unordered state update still operates sequentially. To further enhance performance, transitioning from unordered to parallel state updates would enable transaction execution and state updates to occur simultaneously, unlocking even greater efficiency and scalability.
Prediction based TxDAG for block builder
The current TxDAG+PEVM implementation relies on a block synchronization node, with the TxDAG generated during block creation by the block builder. As a result, the block builder cannot access the TxDAG beforehand, limiting the PEVM’s effectiveness for this type of node.
To overcome this limitation, we are exploring the generation of a pre-TxDAG for the block builder. While this pre-generated TxDAG might not be entirely accurate, it must adhere to specific rules:
- No false negatives: If the TxDAG shows no dependencies, there must genuinely be none.
- Possible false positives: The TxDAG may indicate dependencies that don’t actually exist.
This approach allows the block builder to utilize parallel execution, improving performance. The builder can then refine the TxDAG, optimizing it for use by block synchronization nodes.

")
")
{kind=link}